接下来三篇博客将回顾编译原理课程的大作业(编译一个语义极简的画图语言),分别从词法、语法、语义三部分进行梳理。
绘图语言介绍 <1> 实现简单函数绘图的语句
循环绘图(FOR-DRAW)
比例设置(SCALE)
角度旋转(ROT)
坐标平移(ORIGIN)
注释 (– 或 //)
<2> 屏幕(窗口)的坐标系
左上角为原点
x方向从左向右增长
y方向从上到下增长(与一般的坐标系方向相反)
<3> 函数绘图源程序举例
FOR T FROM 起点 TO 终点 STEP 步长 DRAW(横坐标, 纵坐标);
令T从起点到终点、每次改变一个步长,绘制出由(横坐标,纵坐标)所规定的点的轨迹。
FOR T FROM 0 TO 2*PI STEP PI/50 DRAW (cos(T), sin(T));
该语句的作用是令T从0到2*PI、步长 PI/50,绘制出各个点的坐标(cos(T),sin(T)),即一个单位圆。
语句满足下述规定(原则):
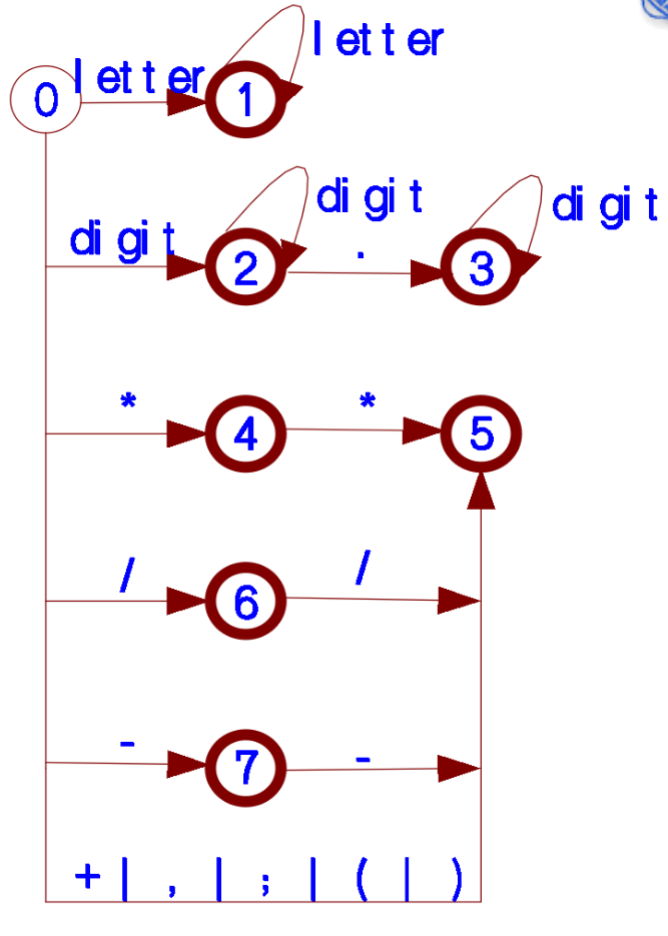
词法分析器的构造
步骤:正规式-NFA-DFA-最小DFA-编写程序-测试
三个任务
滤掉源程序中的无用成分
记号的组成:记号的类别 和属性
本简易编译器使用java来构造
函数绘图语言中记号的分类与表示 private static final String[] Token_Type = {
正规式 letter = [a-zA-Z]
COMMENT = “//“|”–”“ )?
DFA
程序思路及代码 思路非常简单,单个单个读取字符,根据DFA匹配,并赋值给Token,以产生记号流给予语法分析器分析。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 import java.io.*;class Token public String type="" ;public String lexeme="" ;public double value;public class OutputToken static Token[] tokens = new Token[1000 ];private static final String[] Token_Type = {"ORIGIN" , "SCALE" , "ROT" , "IS" , "TO" , "STEP" , "DRAW" , "FOR" , "FROM" , "T" , "SEMICO" , "L_BRACKET" , "R_BRACKET" , "COMMA" ,"PLUS" , "MINUS" , "MUL" , "DIV" , "POWER" , "FUNC" , "CONST_ID" , "NONTOKEN" , "ERRTOKEN" public int Cifa_Analyzer () throws IOException "/Users/leo/Desktop/test.txt" ;new FileInputStream(pathName);new BufferedReader(new InputStreamReader(fis));"" ;"" ;while ((temp = br.readLine()) != null ) {'\n' ;char [] chars = string2.toCharArray();for (int j = 0 ; j < 1000 ; j++) new Token();int k = 0 ;for (int i = 0 ; i < string2.length(); ) {if ((chars[i] >= 65 && chars[i] <= 90 ) || (chars[i] <= 122 && chars[i] >= 97 )) {"ID" ;0.0d ;while ((chars[i] >= 65 && chars[i] <= 90 ) || (chars[i] <= 122 && chars[i] >= 97 )) {else if (chars[i] >= 48 && chars[i] <= 57 ) {"CONST_ID" ;while (chars[i] >= 48 && chars[i] <= 57 ) {if (chars[i] == '.' ) {else {continue ;if (chars[i] >= 48 && chars[i] <= 57 ) {while (chars[i] >= 48 && chars[i] <= 57 ) {else {return 0 ;else if (chars[i] == '*' ) {if (chars[i + 1 ] == '*' ) {"POWER" ;"**" ;0.0d ;2 ;else {"MUL" ;"*" ;0.0d ;else if (chars[i] == '/' ) {if (chars[i + 1 ] == '/' ) {2 ;while (chars[i] != '\n' ) { if (i == string2.length()) {return k;else {"DIV" ;"/" ;0.0d ;else if (chars[i] == '-' ) {if (chars[i + 1 ] == '-' ) {"COMMENT" ;"--" ;0.0d ;2 ;while (chars[i] != '\n' ) { if (i == string2.length()) {return k;else {"MINUS" ;"-" ;0.0d ;else if (chars[i] == '+' ) {"PLUS" ;"+" ;0.0d ;else if (chars[i] == ',' ) {"COMMA" ;"," ;0.0d ;else if (chars[i] == ';' ) {"SEMICO" ;";" ;0.0d ;else if (chars[i] == '(' ) {"L_BRACKET" ;"(" ;0.0d ;else if (chars[i] == ')' ) {"R_BRACKET" ;")" ;0.0d ;else if (chars[i] == 9 || chars[i] == '\n' || chars[i] == ' ' ) {else {" 词法错误 " + "位置:" + k);return 0 ;"SIN" , "COS" , "TAN" , "LN" , "EXP" , "SQRT" };for (int kk = 0 ; kk < k; kk++) {for (int ii = 0 ; ii < 10 ; ii++) {if (tokens[kk].lexeme.toUpperCase().equals(Token_Type[ii])) {break ;for (int ii = 0 ; ii < functions.length; ii++) {if (tokens[kk].lexeme.toUpperCase().equals(functions[ii])) {"FUNC" ;if (tokens[kk].lexeme.toUpperCase().equals("PI" )) {"CONST_ID" ;3.1415926d ;if (tokens[kk].lexeme.toUpperCase().equals("E" )) {"CONST_ID" ;2.71828d ;"NONTOKEN" ;0.0d ;"NONTOKEN" ;if (k > 0 ) {for (int i = 0 ; i < k+1 ; i++) {" " );" " );return k;