第一次实习的总结
本文最后更新于:2 年前
本文记录自己的第一段实习经历。
9.25 - 12.18
职位
算法工程师
第一个月
首先非常感谢wc老师、zc、lhs,让我在XX感受到了很不错的同事氛围,真的很温馨很棒。
两个选择
1.Java开发,负责开发日志聚类后,用户“关注”某些模版后详细展示该模版的信息的功能
2.算法设计,负责对日志流l流向Query容器的行为进行动态扩缩容算法设计
其实自己研究生也不是很想做算法,未来还是想做开发岗方向,但基于两个因素,一是自己没有学习过SpringBoot框架,对Kafka、Zookeeper、ES、Redis、etcd都不太了解,而且,自己身处XXX,部署环境在云端,k8s、容器等知识也都不是很会,实在是压力有点大。 二是自己的导师是做AI算法的,感觉可以学到更多东西。所以权衡了一下还是选择了偏向算法的岗位。
在这里就真的觉得自己运气不错,别的实习生可能会面临调岗,但我自己竟然可以有选择的余地,真的很棒。
开始工作
其实已经到了10.12号,我才确定了自己的方向
对于算法的任务,首先就是要对数据有理解,有深刻的理解!我们能拿到什么数据,该怎么分析这些数据,这就是第一步:看懂数据。
然后对于数据,尤其在公司里,一定会和其他同事有所沟通交流,为了让别的同事能理解我们所做的工作,我们需要一个demo去展示。 其实数据可视化展示也可以帮助我们自己更好得理解数据!可视化其实也是一个很有深度的研究领域。
最后可以不断对自己的算法进行优化,这种优化会在demo中有所体现。
对于我的这个项目,可以比较轻松的从普罗米修斯上获取到现网监控数据,所以不用担心数据的问题。
对于算法而言,参照一些论文,Google对于类似问题采用的是贪心算法,其实也达到了一个不错的效果,所以我们的想法就是MVP(最小可行性产品)就想采用贪心算法。
对于可视化,我才用python Flask+pyecharts绘制,确实都是从头学起,不过flask非常简单,主要要学习的其实是Javascript的DOM还有Jquery框架的使用。
————————————————————————————————————————————
获取数据+数据预处理
写爬虫,爬普罗的数据,其实出现很多问题。AOM限流,难以爬取,暂时沟通还没得到解决方案。
其实数据结构的设计,我们到底要存储什么样的数据,怎样存储感觉是非常有学问的。但其实自己真的理解不深刻,也不知道自己写的好不好… 这点是很难受的
例如路由表的存储结构
一开始我准备像快照一样存储,就分为routing_table和operation_table,定期生成一个完整的routing_table。但导师说这样我得单独开一个线程来做这个工作,消耗太大。最后就采取了单表存储流的所有路由信息。查询时只要挑选各个流距离查询时间最近的那条路由信息即可获得路由表。但其实这样的结构我也不知道未来放入ES中好不好查询,或许未来还得改数据结构..
数据分析
以往路由的变更点、异常点分析
日志流流量分布
Topic流量分布
其实自己不是很喜欢做这个,做得有点难受
UI(这个伴随着整个项目的生命周期,各个阶段都有相应的可视化展示)
做UI前,要思考,要注意展示的点。
而此项目,其实就是要注重原来现网的检测数据和自己的算法数据的这种对比感!
所以用横向条形图,左侧现网右侧算法,这样对比度更加强烈来进行展示。
其实这个月…最后有点懈怠了,很多事情明明知道怎么做好,却没有去做,尤其是数据分析的部分…胶片做的非常烂
和导师的聊天的部分记录
- Python学习路线 Python编程从入门到实践 -> Effective Python/Python Cookbook -> Fluent Python
学习了高效的python写法,一定要去改曾经自己写过的代码,去实现。不然,习惯是很难改变的,好代码的习惯要好好培养。 - 做技术可以2-3年就跳槽,但想做管理不要跳。XX的管理不是别的,一定是老人。
- 2021年,选择一门语言强化,可以再选择另一门语言做深入
- 在XX这样公司,以后就不可能有两周的旅行了,好好去玩玩
- 不要说这个方法 “也行” 多质疑,真的
- Balsamiq Mockup 画图,做胶片的好帮手~
- 外企会对你的职业生涯做规划,告诉你未来给你选择。而在XX3年不知道未来是怎样的。
- 刚进入公司,尤其是XX这样的公司 前半年一定要拼命加班!这样有可能会进入升职的“快速通道”
11.01 - 12.18
为什么提前终止了实习呢…导师在12月初转岗去了另外一个地方,我自然感觉远程指导和面对面还是有相当大的差距。当然公司内部也经历了两次存储架构的改变,自己的心也有些累了。感觉暂时也学不到什么了,做出来的东西没有什么使用价值。于是提前两周结束了实习。
日志存储出现新的架构
为何改变架构?
- 写入和查询在某种情况下时矛盾的
- 要想查询性能高,要求ES索引足够小(同样的日志流量,索引小意味着索引会变多)
- 写入性能高,要求同时写入的索引不能太多
- 当前索引现状(问题)
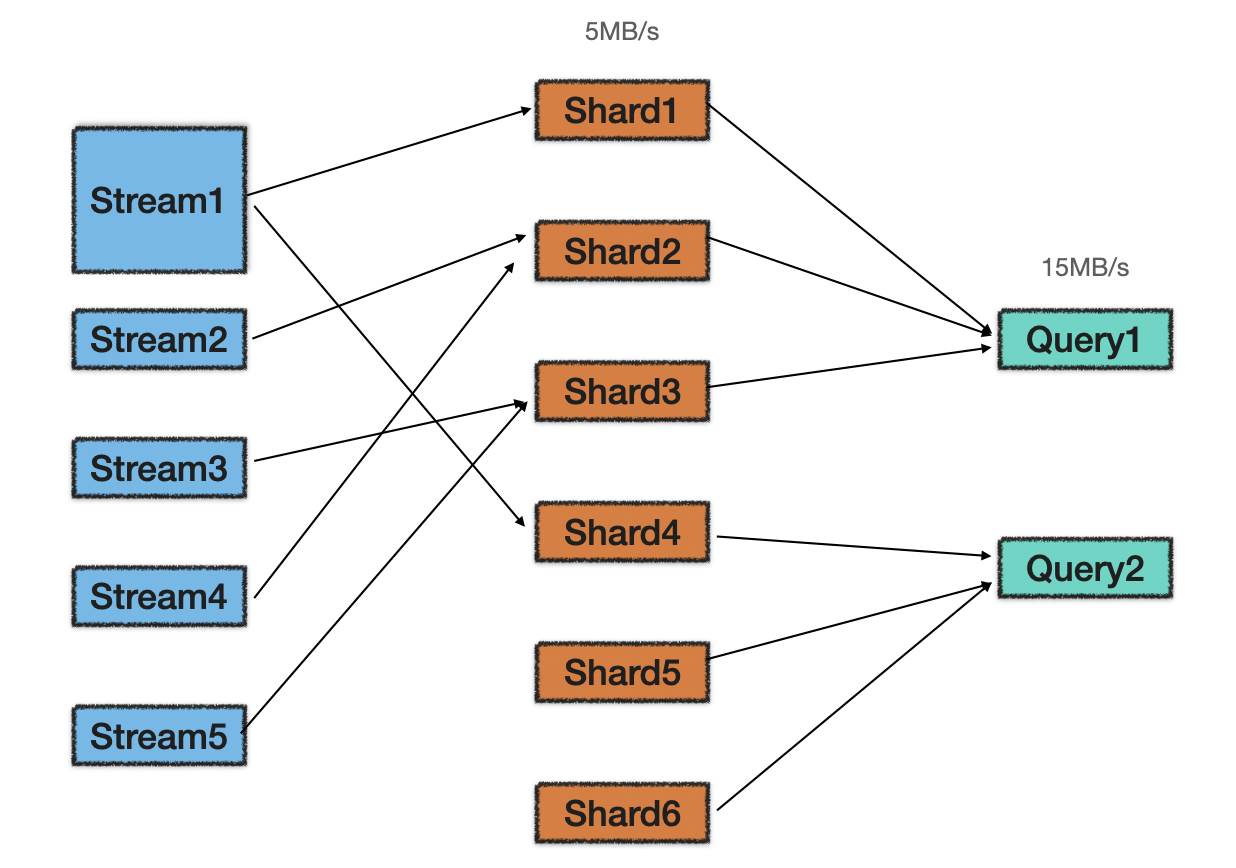
- 建立stream到shard数据流的动态均衡映射
- 将大象流与老鼠流合并或切分为统一固定流量的shard数据流
- 日志流按照租户遍历映射到指定大小的shard中
- 实时动态调整shard和日志流的映射关系(流量波动)
- Move次数少
- 超过shard流量阈值的数据流切分到不同节点
- 小于shard流量阈值的租户数据在同一个shard内
- …(具体可以用贪心BFD…)
- 利用自动路由算法将shard路由到不同的query消费族(自动路由就变成了一个经典装箱问题)
- query根据分配到自身的shard数据流建立shard到index的一一映射关系,自身不再做shard分裂,仅做线程间均衡
缺点
- 数据非租户级隔离
- 未命中场景查询效率会更加劣化(各种租户查询会落在同一个索引,大小租户的查询会互相影响)
- 解决方案
- 标记历史查询条件
- shard流映射时大小租户做区分
- 解决方案
优点
- 写入性能达到最优(因为shard与query映射固定,索引数量控制在一个固定的数值下)
- 查询性能可做到基线化
- 分配和路由算法更简单
Sharding UI
这次直接使用echarts画了,其实更加方便了,因为echarts文档更加丰富翔实。
UI设计目标
- 同时体现query流量分布均匀情况与shard流量分布
UI设计思路
- 查看了各个现网region的query数量,基本在20-30+的数量,乘上10也就是200-300+的shard,所以想直接呈现分布情况(除非用华夫饼图,但不够详细)不太可能。
- query和shard存在映射关系,这个关系可以绑定在点击query就显示流向这个query的10个shard的流量分布
最终实现
- 正轴:query流量分布画柱状图(20-30个bar)
- 负轴:各个query内的10个shard流量方差
- 交互:点击query的bar,可以显示query内10个shard的流量分布柱状图(10个bar)
这样可以在一目了然query和shard的分布情况。也不丢失任何数据具体情况。
突然…导师告知要转岗…
整合demo
- 将以前实习生的自动基线的代码(基于Django)整合到我们ilog(基于Flask)里
整合其实也是一个重构的过程,在整合中其实就发现,什么样的代码易于整合,什么样的代码几乎要重写。这也是我未来要有所注意,要去研究的。
为了做自动基线的存储也学了一下ElasticSearch的使用,这东西怪好用的,未来学学底层原理。
为老师Crux功能做个简单的UI测试
主要借助BootstrapTable进行表格的呈现(同时该支持父子表)
把所有项目部署在196节点上
python这语言真是不能更新,不小心更新,anaconda都崩溃了…
下班前最后跑服务还是nohup …… &让服务跑在后台吧,以防ssh各种莫名其妙的原因断了
自己来设计sharding_init算法+rebalance等各个调度策略算法
第一次接触到了cplex(这个要付费),之后尝试了一些类似scip,glpk等开源的算规划问题的数学工具
基本上做这种研究问题就是分三步
- 用cplex跑一下我们要优化的目标函数(看模型、程序有没有大问题)
- 优化模型,简化目标函数,让cplex跑得更加流畅?例如将非线性目标规划转换成线性的(保证极值点不变)。其实这个时候如果cplex解的快,就可以端到端用cplex引擎。
- 如果觉得cplex跑得太慢,就可以用一些heuristic的方法缩短时间(当然精度有所欠缺,保留在一个可以接受的范围就行)。这种heuristic的方法更多就是对自己的目标,有更加特性化的解决方法。这完成了,一篇优化论文就完成啦。
自己借鉴了一些VM Migration的论文去考虑shard的调度。
主要参考Multi-objective optimization for rebalancing virtual machine placement此篇
这个实习总结的文章就不专注于论文本身了,其实我觉得这论文也没有什么深挖的必要。
总之,我们做调度要考虑以下四个问题:
- 如何初始化映射关系
- 新增的流怎么分配
- 如何rebalance(如何判断unbalance)
- shard超过阈值后如何迁移
其实蛮难的这些问题…无奈导师走了,实习还是得结束了,其实这些问题是算法的核心问题。做了一堆UI来验证算法的可行性但算法只写了简单的贪心装箱…哎,一大遗憾啊。
Todo…. 毕设时再进行一些相关研究
和导师(或同事)的聊天的部分记录
- 做PPT当个处女座吧,展示20页,backup这种过程中生产的胶片可能至少有50页(这种更详细的内容很适合做凝缩后的数据支撑)
- 不要说 “我原来怎么想的”,请写下来。在脑子的东西是靠不住的模糊的。
- 说话,或者写句子。先说论点,再说论据。
- 设计一个方法时,预设太多,往往最后的功能就很有限了
- 工程师一定要软硬结合来考虑性能
- 一个印度四十多岁做业务的,在别人讲完需求后,会紧接着先讲一遍要做的业务,再由此衍生出其他场景去质问提需求的人为什么做,为什么不做。其实我觉得就是做工程或者做算法,都一定要好好去理解业务!!
- 做工程,很多时候要专注模型问题,这是最难的也是最重要的。
- 数据怎么存很大程度归决于数据怎么用。
- 在公司里,还是必须得有不错的定位问题的能力。
实习总结
加过班,熬过夜,生过病,在公司睡过觉。但早上闹钟没响干脆请假这种事也干过。
导师转岗,自己也无奈提前离职。
不过还是学到了公司的很多为人处事。
技术确实没学到什么新的(前端/巩固了python)不过这段时间在学校估计浪费也会很严重吧hh。
第一次实习,面对全新的环境,还是收获很大的,说不上来。 对未来的路更坚定了吧!
部门比公司更重要
写在最后
软件开发者大会,听了以下一些领域的大牛的演讲…继续摸索吧…
- Serverless
- 分布式数据库/云数据库
- 区块链
- 重构与建模…
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!