操作系统内存管理
本文最后更新于:2 年前
自实习结束已有近9个月没有更新博客了,这段时间主要在进行毕业设计和毕业旅行噗,毕设做的微服务相关内容暂时不准备整理至博客上。暑假主要稳固基础知识(计算机组成原理、操作系统、计算机网络、数据库原理),弥补本科的缺陷。接下来会更新关于操作系统的相关内容。
内存管理
目录
- 物理地址与虚拟地址
- 内存分段与分页管理
- 内存组织、分配与释放
- 小块内存的管理
- 虚拟内存技术
- 垃圾收集
物理地址与虚拟地址
在CPU实模式下(16位),程序对于内存的访问直接使用物理地址。随着地址线增多,程序并发要求变高,程序与程序之间地址冲突的各种问题就急需解决了。我们给每个程序一样的虚拟地址空间,通过翻译单元(硬件MMU)将虚拟地址翻译成物理地址。
那么如何设计这个映射关系表呢但是如果通过一一映射的地址翻译表。在32 位地址空间下,4GB 虚拟地址的地址关系转换表就会把整个 32 位物理地址空间用完,这显然不行。要是结合前面的保护模式下分段方式呢,地址关系转换表中存放:一个虚拟段基址对应一个物理段基址,这样看似可以,但是因为段长度各不相同,所以依然不可取。综合刚才的分析,系统设计者最后采用一个折中的方案,即把虚拟地址空间和物理地址空间都分成同等大小的块,也称为页,按照虚拟页和物理页进行转换。根据软件配置不同,这个页的大小可以设置为 4KB、2MB、4MB、1GB,这样就进入了现代内存管理模式——分页模型。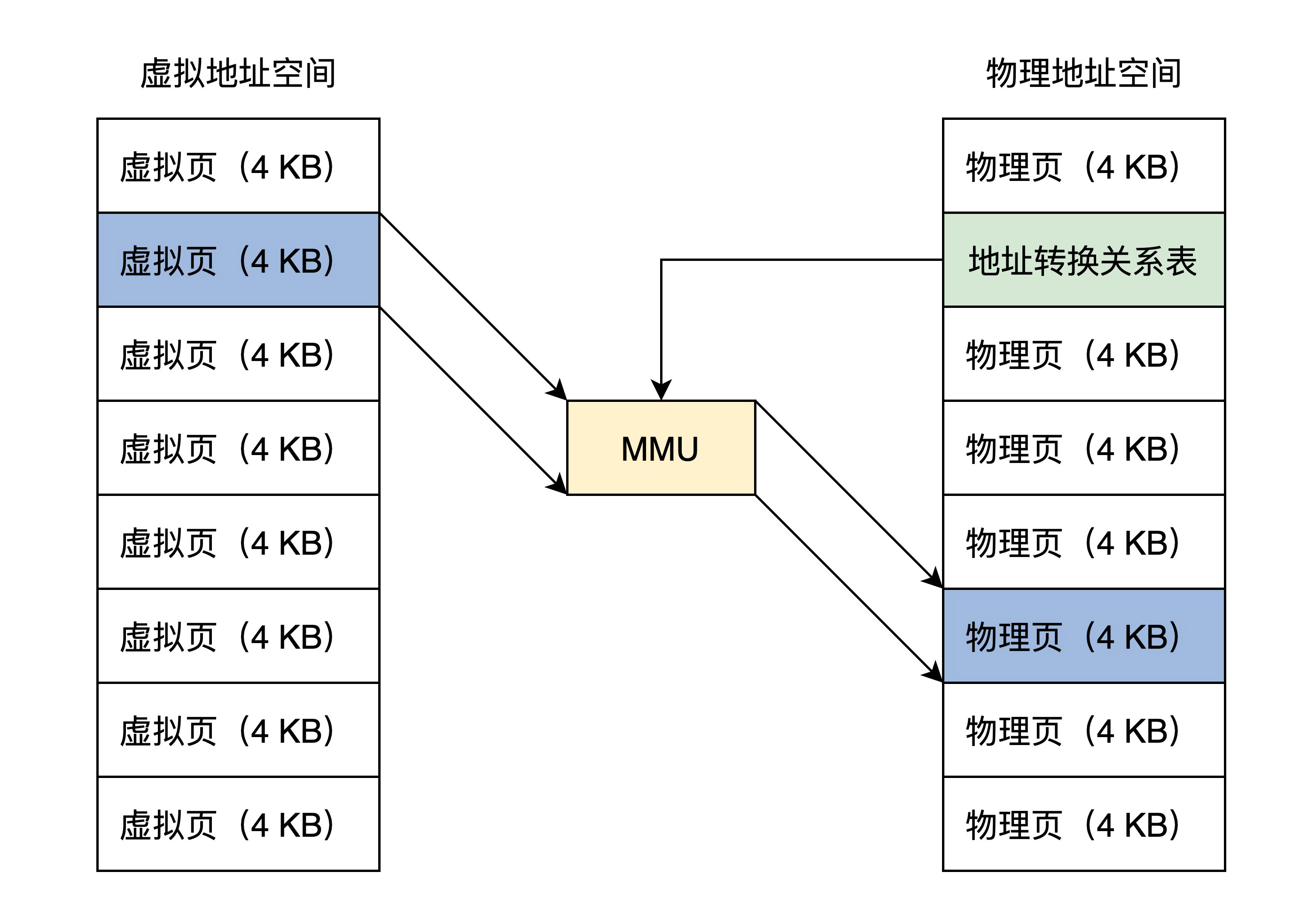
一直存在内存中的地址关系转换表也就是我们熟悉的页表,其基地址放置在CR3寄存器当中,所以当程序切换(进程切换时)也要修改CR3寄存器的值。最后,当CPU接受到虚拟地址时,将虚拟地址与页表首地址传入MMU即可返回真正的物理地址。
内存分段与分页管理
前文已经讨论了一部分选择分段还是分页管理内存的问题,但还不足够。(我认为,分页是真正起效的内存管理模式,分段只是逻辑上的划分起到的作用极小甚至没有)。为何这么说,那得从分段的历史说起,分段最开始是从Intel的8086CPU,受限于价格和技术水平,当时的CPU和寄存器的宽度仍然为16位。那时还是直接访问物理地址的,为了便利地实现多道程序并发运行,也就需要支持对各个程序进行重定位,因为如果不支持重定位,凡是涉及到内存访问的地方都需要将地址硬编码,进而必须把某个程序加载到内存的固定区间。有了分段机制,程序中只需要使用基于段的相对地址,然后更改段基址,就可以方便地对程序进行重定位。当然,在8086CPU中,分段除了服务于重定位的目的,还有其他的作用。具体地说,8086CPU的地址线宽度是20位,可寻址的最大内存空间是1MB,但寄存器这些都是16位, 它是通过段加偏移的方式生成20位的地址,从而实现对1MB内存空间的寻址的。我们经常谈的程序可执行文件的分段,例如代码段数据段这些,在最开始其实就是为了跟上面描述的硬件上的内存分段机制对应,并且逻辑上能够更清晰有序地构造程序的组织结构。
但是分段管理从表示方式和状态确定角度、内存碎片、内存和硬盘的数据交换效率(段长度不同,很可能导致系统性能抖动)考虑来看均有很大的缺点,当然段最大的问题还是使得虚拟内存难以实施。虚拟内存会在之后的段落详细描述。
目前Linux的分段更多的是一种历史包袱,而不是能够提供多大实际作用的内存管理机制。
分页管理下的MMU页表原理
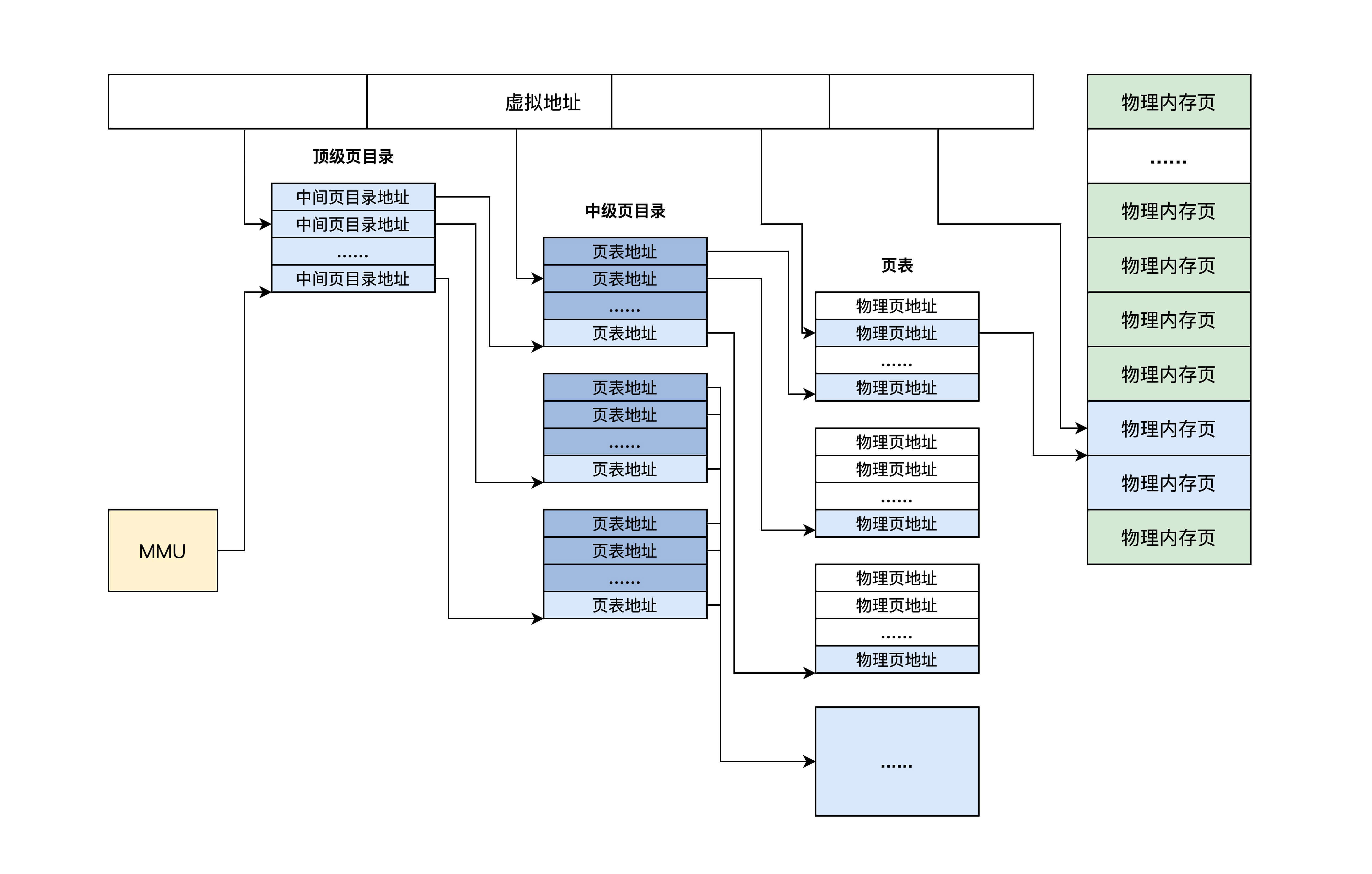
从上面可以看出,一个虚拟地址被分成从左至右四个位段。第一个位段索引顶级页目录中一个项,该项指向一个中级页目录,然后用第二个位段去索引中级页目录中的一个项,该项指向一个页目录,再用第三个位段去索引页目录中的项,该项指向一个物理页地址,最后用第四个位段作该物理页内的偏移去访问物理内存。这就是 MMU 的工作流程。
为什么要分成这么多级的页表呢? 主要为了节省内存,页表也是需要占用空间的,一级页表是必须放在主存之中的,但页表分级之后二级页表便可以存储在磁盘之中,不用占用内存空间。同时,如果一级页表的某些页项为空,则对应的二级页表也无需进行创建。
内存组织、分配与释放
这部分将详细介绍与设计一个实际的分页内存管理。此部分参考LMOS操作系统课程。
首先要想好页的数据结构需要包含哪些信息:页的状态、页的地址、页的分配记数,页的类型、页的链表。其中链表是方便挂入其他组织页面的数据结构之中所用。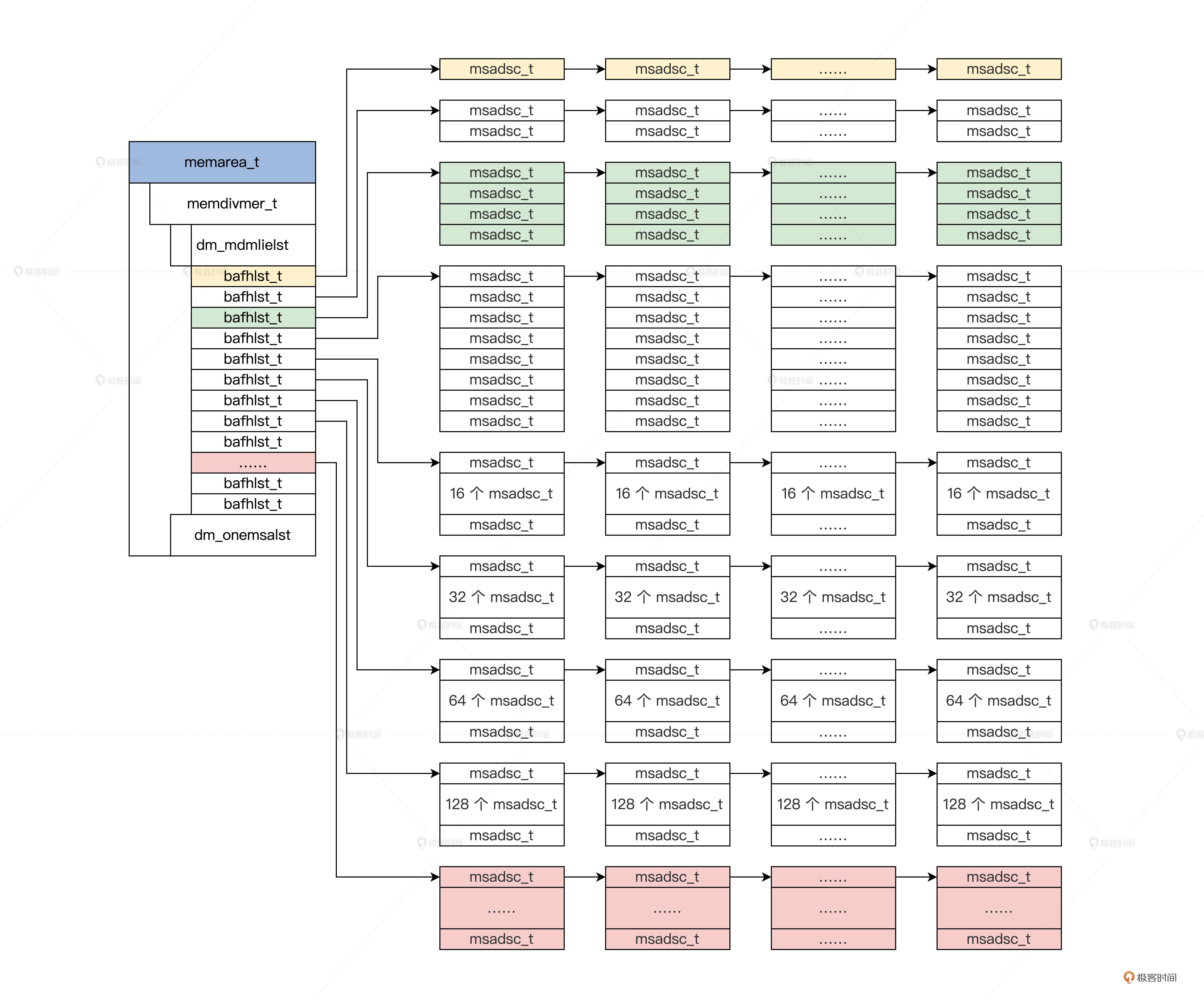
dm_mdmlielst 数组挂载连续 msadsc_t 结构的数量等于用 1 左移其数组下标,如数组下标为 3,那结果就是 8(1<<3)个连续的 msadsc_t 结构。因此页面数统统都是 2 的倍数,这样就能实现页内存对齐,减少内存分配时的碎片。同时,2的倍数意味着可以用位操作进行相应计算工作,这比乘法操作要节省较多的CPU时钟。
根据这个页面的组织结构,即可设计出相应的页面分配算法。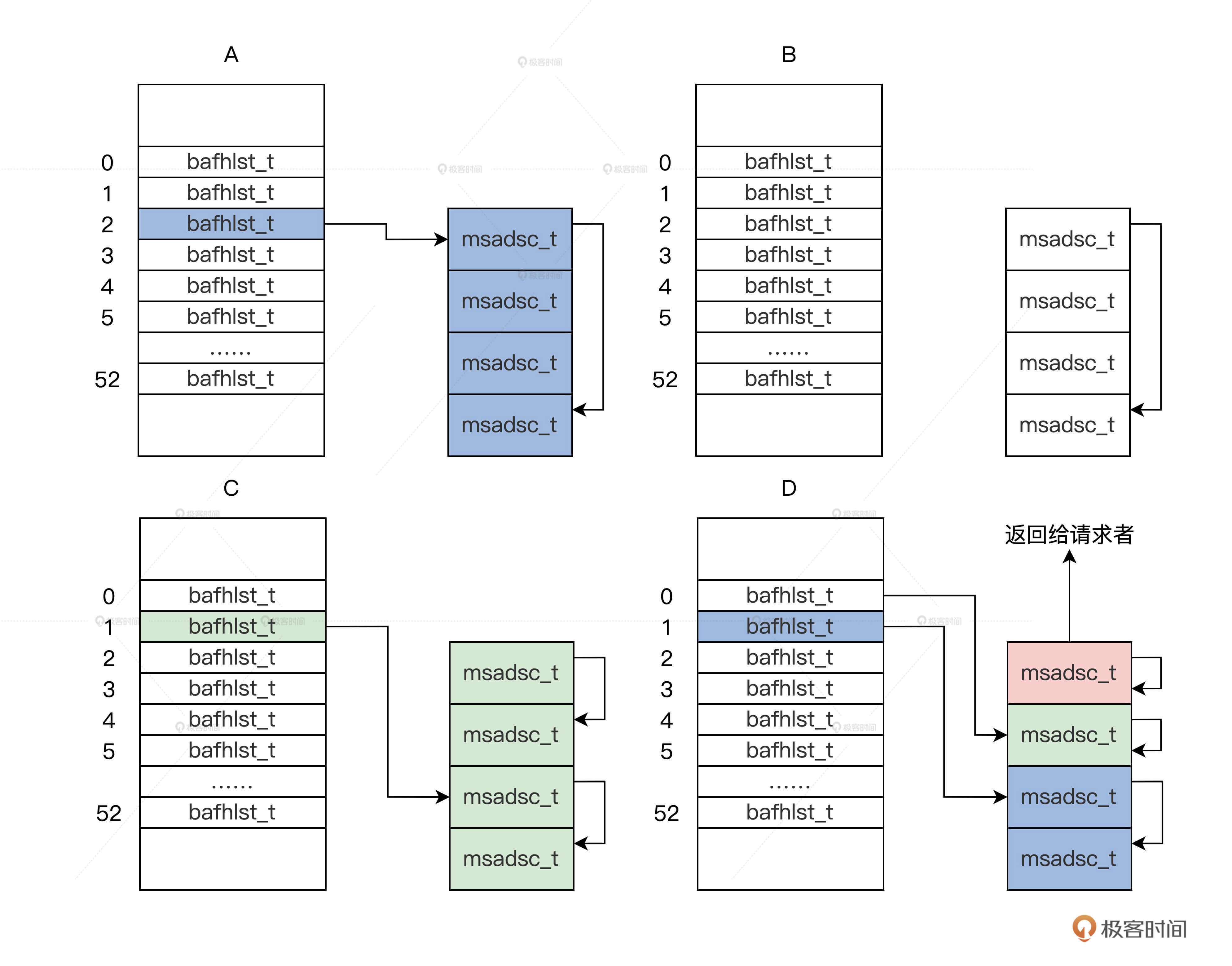
假设现在需要分配一个页面。
- 根据一个页面的请求,会返回 m_mdmlielst 数组中的第 0 个 bafhlst_t 结构。
- 如果第 0 个 bafhlst_t 结构中有 msadsc_t 结构就直接返回,若没有 msadsc_t 结构,就会继续查找 m_mdmlielst 数组中的第 1 个 bafhlst_t 结构。
- 如果第 1 个 bafhlst_t 结构中也没有 msadsc_t 结构,就会继续查找 m_mdmlielst 数组中的第 2 个 bafhlst_t 结构。
- 如果第 2 个 bafhlst_t 结构中有 msadsc_t 结构,记住第 2 个 bafhlst_t 结构中对应是 4 个连续的 msadsc_t 结构。这时让这 4 个连续的 msadsc_t 结构从第 2 个 bafhlst_t 结构中脱离。
- 把这 4 个连续的 msadsc_t 结构,对半分割成 2 个双 msadsc_t 结构,把其中一个双 msadsc_t 结构挂载到第 1 个 bafhlst_t 结构中。
- 把剩下一个双 msadsc_t 结构,继续对半分割成两个单 msadsc_t 结构,把其中一个单 msadsc_t 结构挂载到第 0 个 bafhlst_t 结构中,剩下一个单 msadsc_t 结构返回给请求者,完成内存分配。
页面释放算法即是分配的逆算法,这里就不再阐述了。
小块内存的管理
内存是非常宝贵的,如果程序申请的内存远远小于一个页面的大小,此时该如何分配内存呢?
这部分直接介绍Linux的Slab分配器,我们来看看Linux是如何解决这个问题的。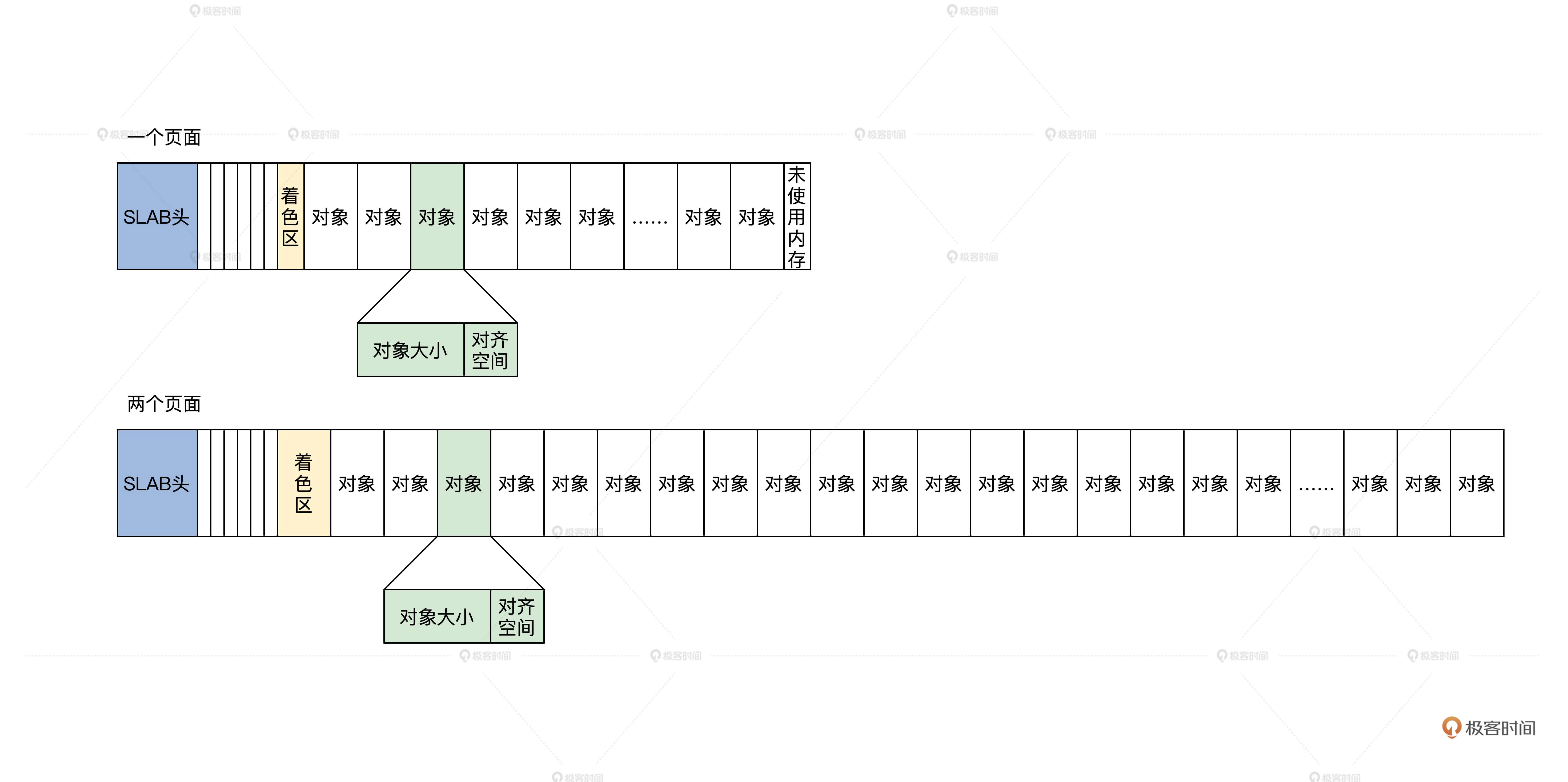
在 SLAB 分配器中,它把一个内存页面或者一组连续的内存页面,划分成大小相同的块,其中这一个小的内存块就是 SLAB 对象,但是这一组连续的内存页面中不只是 SLAB 对象,还有 SLAB 管理头和着色区。这个着色区也是一块动态的内存块,建立 SLAB 时才会设置它的大小,目的是为了错开不同 SLAB 中的对象地址,降低硬件 Cache 行中的地址争用,以免导致 Cache 抖动效应,整个系统性能下降。
最后提及一下Slab对象的大小:Slab分配最小位32B,最大分配单元依赖体系架构。
虚拟内存技术
一个英语往往拥有很大的连续地址空间,并且每个应用都是一样的,只有在运行时才能分配到真正的物理内存,在操作系统中这称为虚拟内存。
虚拟地址就是逻辑上的一个数值,而虚拟地址空间就是一堆数值的集合。通常情况下,32 位的处理器有 0~0xFFFFFFFF 的虚拟地址空间,而 64 位的虚拟地址空间则更大,有 0~0xFFFFFFFFFFFFFFFF 的虚拟地址空间。
虚拟地址空间某种角度也可以称为进程地址空间,关于进程地址空间的描述将留到下一篇操作系统进程中详解。
对于虚拟内存技术,便会存在页面存在内存之中与页面存在磁盘之中的区别。虚拟地址传入CPU后查询页表的过程中自然也就存在页命中与页丢失两种情况。下图展示了页命中的情况,图摘自CSAPP。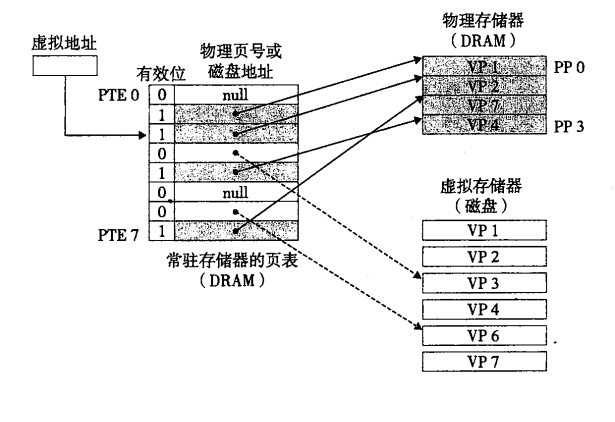
如果页缺失,则将调用内核中的缺页异常处理程序,该程序会选择一个牺牲页将其复制回磁盘(这里也涉及很多调换算法,常见的有LRU算法等),接下来将缺失的页面换到内存中。当异常处理程序返回时,CPU会重新启动导致缺页的指令,该指令会把导致缺页的虚拟地址重新发送到地址翻译硬件。此时就能页命中了。
或许到此就会产生一个感觉,虚拟内存技术效率有点低,因为不命中的惩罚很大,我们担心页面调度会破坏程序性能。实际上,虚拟内存工作得相当得好,这主要归功于局部性,关于局部性就不多说啦。
垃圾收集
垃圾收集器将内存视为一张有向可达图,其中具有两种节点:
- 根节点(Root Node):对应于不在堆中但包含指向堆中的指针,可以是寄存器、栈中变量或全局变量等等。
- 堆节点(Heap Node):对应于堆中的一个已分配的块。
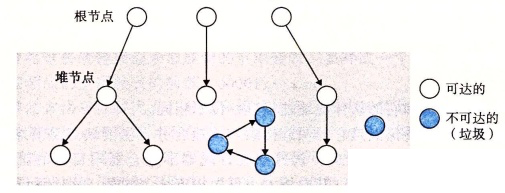
对于像ML和Java语言,其对指针创建和使用有严格的要求,由此来构建十分精确的可达图,所以能回收所有垃圾。而对于像C和C++这样的语言,垃圾收集器无法维护十分精确的可达图,只能正确地标记所有可达节点,而有一些不可达节点会被错误地标记为可达的,所以会遗留部分垃圾,这种垃圾收集器称为保守的垃圾收集器。
下面介绍具体的垃圾收集流程。Mark&Sweep垃圾收集器由标记阶段与清除阶段组成,标记阶段标记出根节点的所有可达和以分配的后继,而后面的清除阶段释放每个未被标记的已分配块。块头部中空闲的低位中的一位通常用来表示这个块是否被标记了。
标记阶段为每个根节点都调用一次mark函数,首先会判断输入p是否为指针,如果是则返回p指向的堆节点b,然后判断b是否被标记,如果没有,则对其进行标记,并返回b中不包含头部的以字为单位的长度,这样就能依次遍历b中每个字是否指向其他堆节点,再递归地进行标记。这是对图进行DFS。
清除阶段会调用一次sweep函数,它会在所有堆节点上反复循环,如果堆节点b是已标记的,则消除它的标记,如果是未标记的已分配堆节点,则将其释放,然后指向b的后继节点。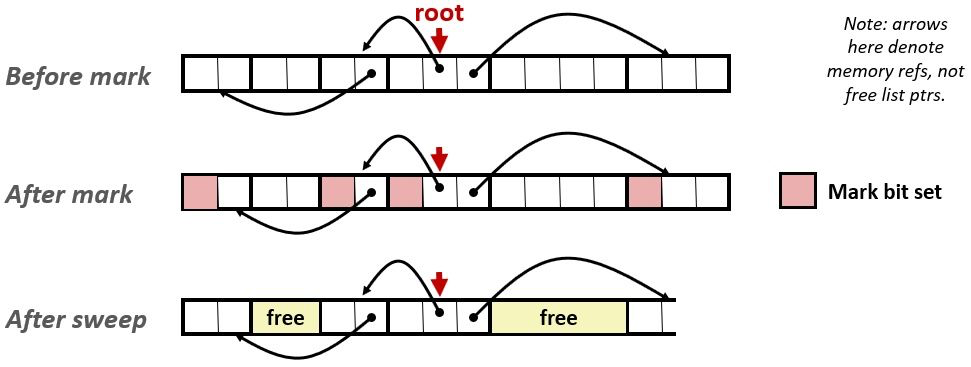
参考内容
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!