CMU15-445课程知识点复习 & 总结
本文最后更新于:2 年前
本文将进行CMU15-445的知识点巩固与复习。
复习点参考博主:西部小笼包与一份很不错的数据库笔记进行整理,我进行了参考并加入了一点自己的见解。
数据库存储
1. 为什么需要数据库系统?文件系统不够吗?
首先是更好得解耦,对所需存储的数据的建模(不同场景不同模型)这些逻辑可与物理存储层分离。并且类似查询检查保证数据一致性的逻辑也可以与业务代码分离。
其次磁盘IO是比较昂贵的,相较于基于操作系统mmap等机制对于内存磁盘的交互,数据库系统拥有更多的信息去更好地决定何时将内存页刷入磁盘。数据库会有一个Buffer Pool Manager组件进行管理,制定专属的淘汰策略。
2. 数据库底层是如何存储的?
数据库的存储为了移植性一般基于文件系统。DBMS 通常将自己的所有数据作为一个或多个文件存储在磁盘中,而 OS 只当它们是普通文件,并不知道如何解读这些文件。
数据库会按照Page为存储单位进行存储(类似文件系统Block的概念)。每个 Page 带着一个唯一的 id。数据库会用一个间接层做通过PageID <—> 物理实际地址的映射。
数据库会有一个storage manager模块负责读写磁盘上的对应Page,同时保持较好的空间和时间的局部性。数据文件在底层会有不同的组织形式,比较常见的是无序的HEAP FILE, 或者是有序的聚集索引(B树),还有一种是HASH FILE。
3.HEAP FILE 内部是怎么组织变成一个数据库的?
这里不讨论链表的方式,主要讨论页目录(Page Directory)的方式。
这种方式会有一些页目录会记录全部数据文件的位置,同时也记录了每一个页的FREE SLOT数量(即使用情况)。
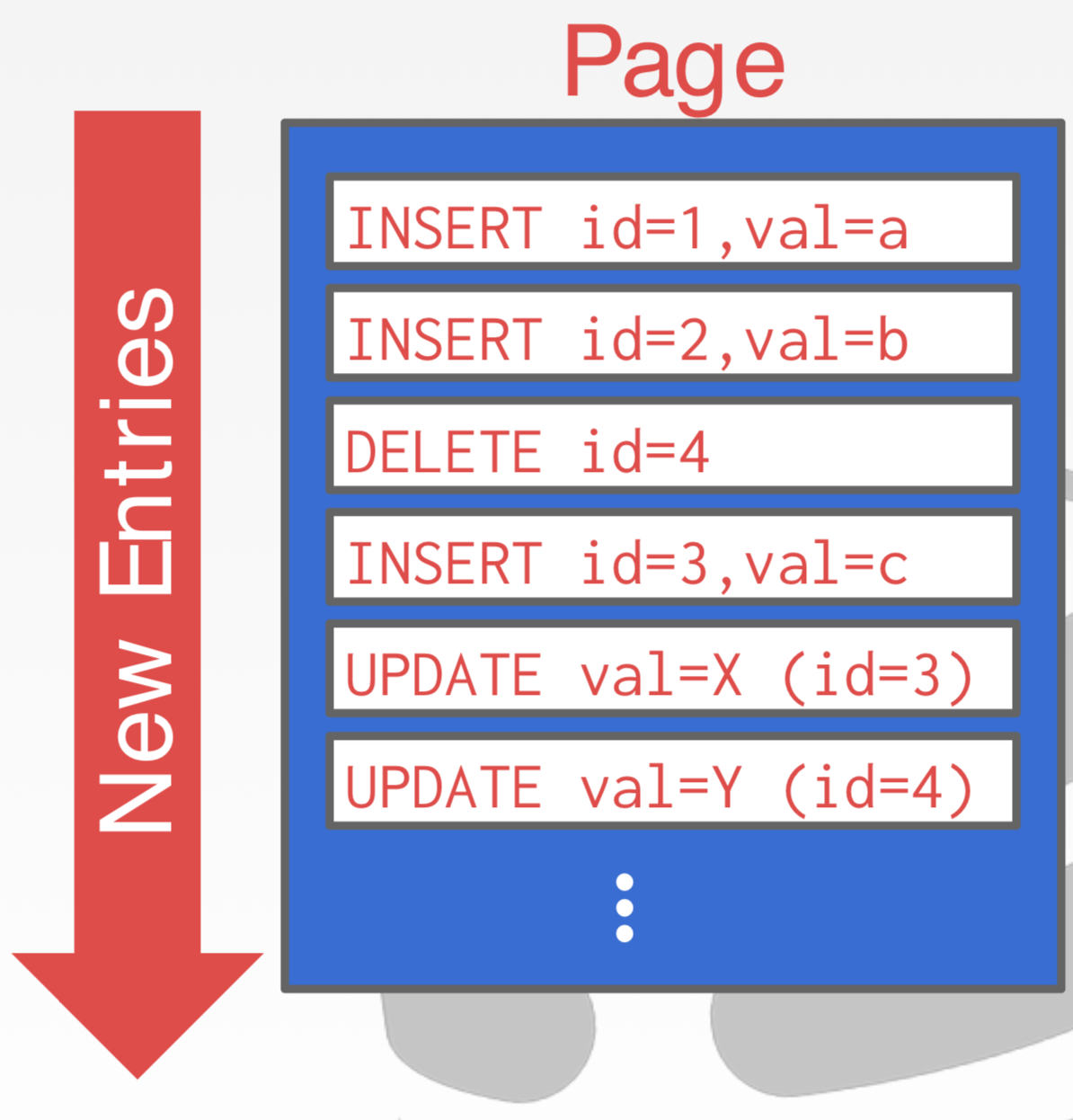
具体数据页的存储有两种方式,一种记录数据本身采用Slotted Page(下左图),另一种记录操作数据的日志(定期会压缩日志)。
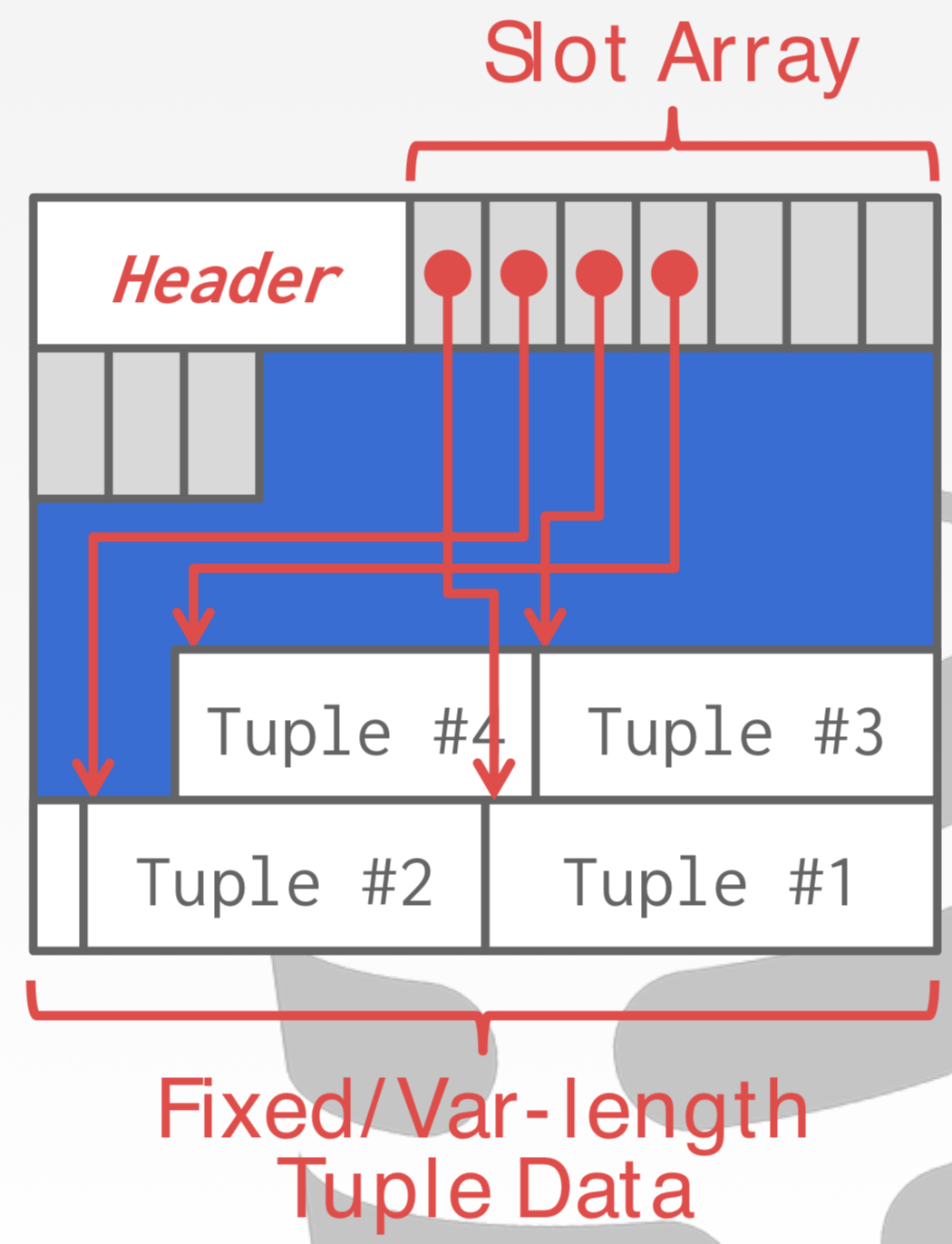
对于Slotted Page,每一个TUPLE 在DBMS里会即会有以page_id + offset/slot的二元组唯一定位。
索引
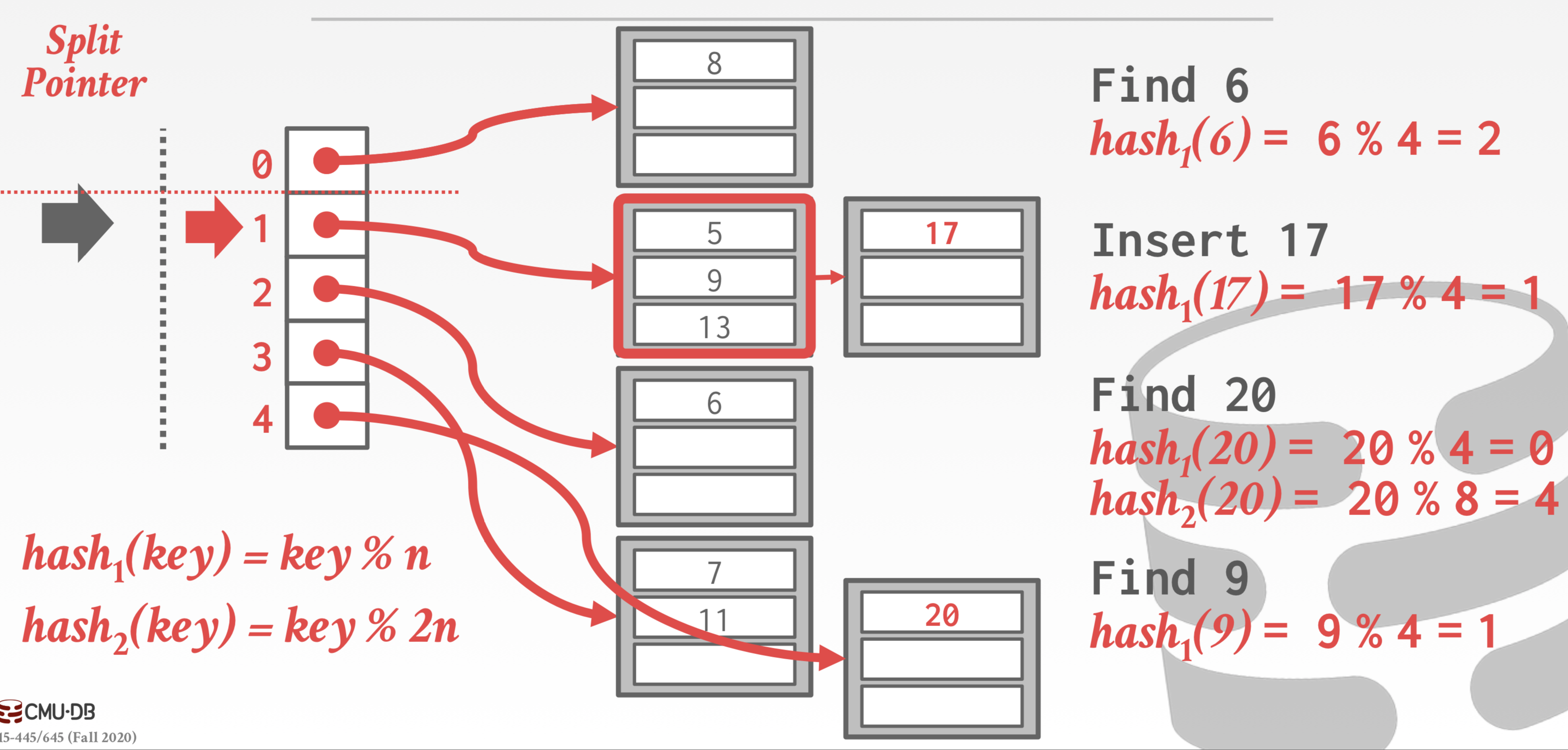
4.Hash表主要关注什么?静态、动态HASH算法有哪些区别是什么?
Hash 函数的选择,就是在性能和冲突率之间的TRADE OFF。另外就是冲突之后的策略选择。其实是在开一个更大的表和找到其他地方去插KEY的TRADE OFF。
静态Hash算法(要求事先知道存多少元素,否则就需要在一定时间对整个表做扩容和缩容然后rehash):
- 线性扫描
- Robin(目的是让每次扫描次数差不多)
- Cuckoo(两张表)
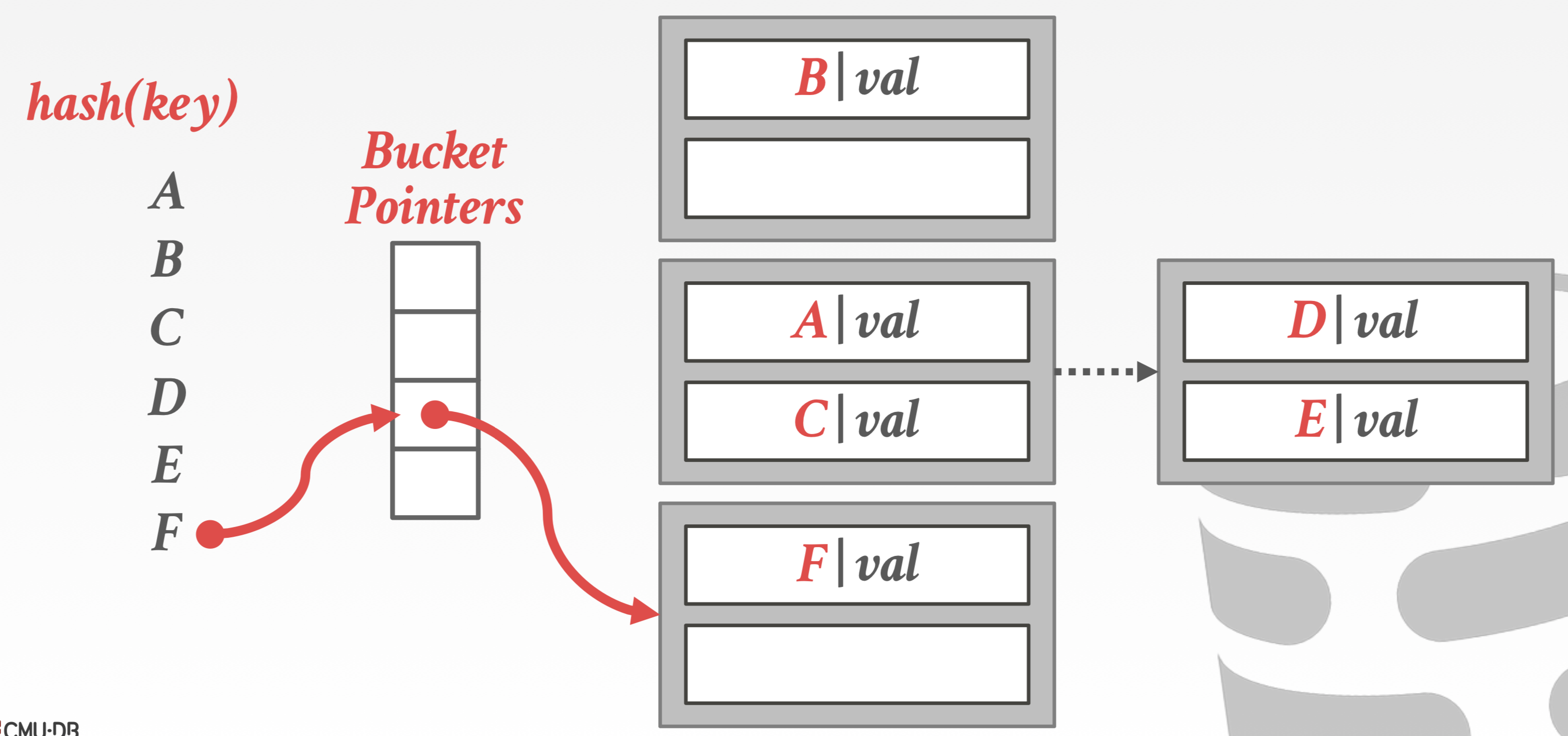
动态扩容的Hash算法:
- Chained Hash (桶满了加桶)
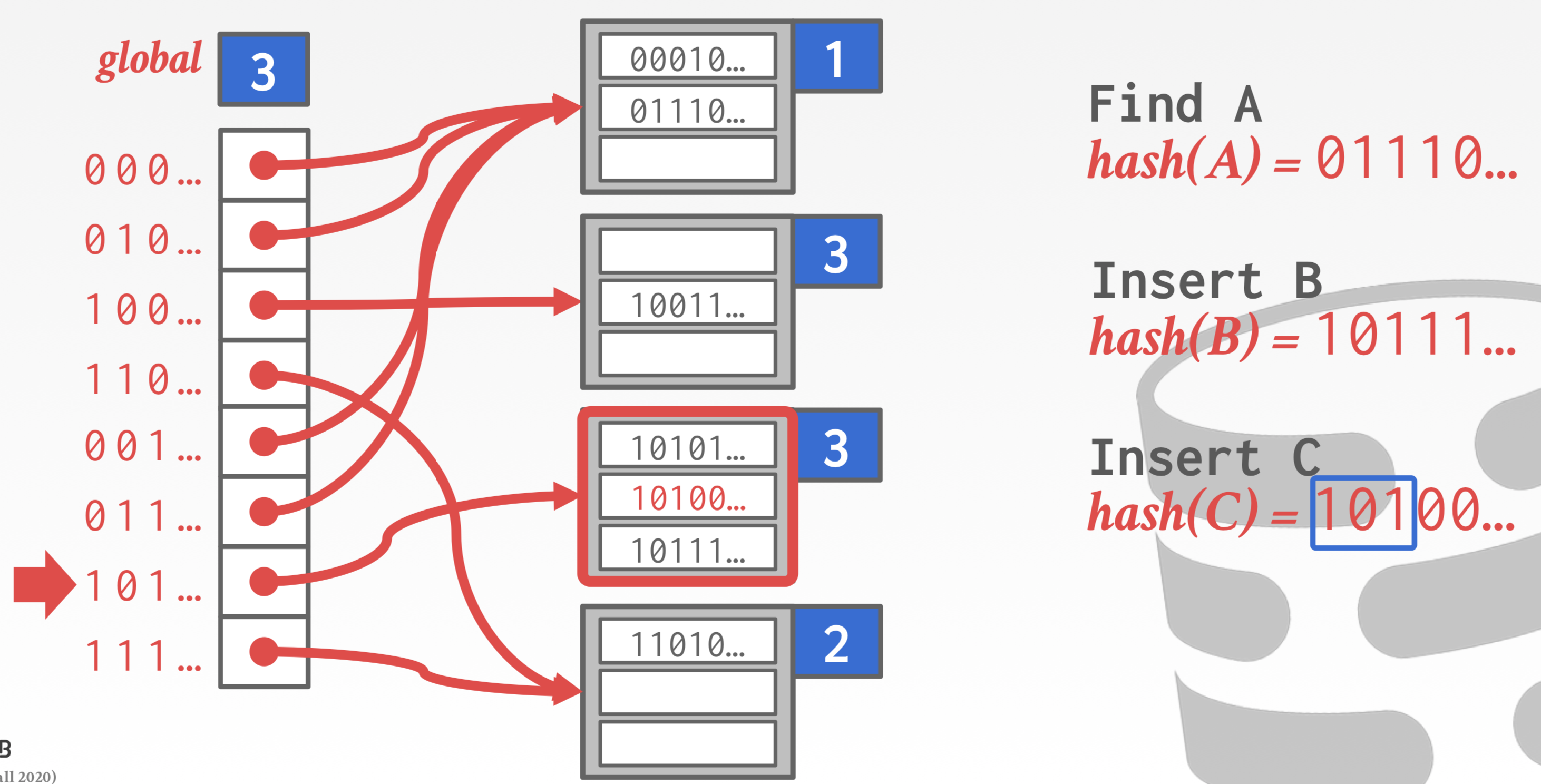
- Extenible Hash(桶满了后增加hash匹配位数,变相增加桶数)
- Linear Hash(维护一个指针指向下一个被拆分的桶)
5. B+树有哪些性质?
- 他是完美平衡的,所有叶子节点的深度一致。
- 每个非根节点至少是半满的。(如果最多有M个孩子,那么至少会有[M / 2 - 1, M - 1]个key )
- 每个内部节点有K个KEY,就会有K + 1个孩子。
6. B+树的设计策略:B树节点的SIZE如何选择?合并阈值?
一般存储设备IO开销越大,速度越慢,节点就需要越大。具体情境下的最优大小由 workload 决定。
对于节点的合并有些 DBMS 选择延迟 merge 操作的发生时间,甚至可以利用其它进程来负责周期性地重建 table index。
7. B+树有哪些常见优化?
1. 前缀压缩,如果这个节点的STRING 都是以ABC,开头,可以把这个ABC提出来,这样之后的信息都会少,就能存更多。
2. 后缀截断【较常用】。如果后缀的信息没有区分度,则在中间节点的时候可以砍掉。
3. 指针调整,如果一个PAGE已经再BUFFER POOL 里PINNED了,我们可以存直接的指针来代替原来存的PAGE ID。来避免去PAGE TABLE 查ADDRESS。
4. 批量插入【常用】。如果一开始你就知道要插的所有KEY,可以对他们先排序,然后对这些KEY去构建INDEX BOTTOM UP。这样性能最好。
8. 什么是聚簇/非聚簇索引、覆盖索引等索引?
聚簇索引:将完整tuple数据保存在叶子节点。
二级索引:又称为辅助索引,不保存tuple行数据,仅包含索引数据及相应主键数据。
覆盖索引:就是建联合索引来保证要QUERY的字段都在索引里有,而不用回表查主键索引。如select name, car from XXX 建立(name, car)的联合索引可以直接拿到数据而不用回主键查.
Todo… 包含索引(index include column)、隐式索引、局部索引、唯一索引。
9. 什么是Latch Crabbing,此方法是如何加锁索引的?
首先拿父PAGE的LATCH, 然后拿孩子的LATCH。如果父节点是SAFE(不会引起分裂、合并操作)的则释放父PAGE的LATCH。
查的时候,拿到孩子的读锁就可以释放父亲的读锁。
删增的时候,拿写锁,如果某一个孩子是SAFE的,可以释放祖先持有的全部锁
其余一个优化是可以先假设叶子节点是安全的,在一开始可以只上读锁。如果发现这个假设是错的,再重头来一遍写锁。
如果要同时支持LEFT->RIGHT, TOP->BOTTM 两个方向的节点查找,当发现锁被占有了,最好的方式是等一小会然后杀掉自己,重头开始。
另一个优化是把PARENT节点的更新延迟到下次获取写锁的时候再更新(通过一个全局变量记录需要更新的节点)。
排序、聚合和Join
10. 如果有108个页,内存只能容下5页,如何做硬盘外排序?
首先每次放进内存5个页,对5个页排序,写到磁盘的一个文件里。这样最后会有22个文件。
下一次开始做K路归并,把4个文件放进去BUFFER里,然后流式读文件。还余下的一个文件的位置是用来当PQ,每次输出一个最小的写进磁盘。这样搞完之后。就还有22/4 = 6个文件。
下一步同样,变成2个文件。最后合到一个有序文件。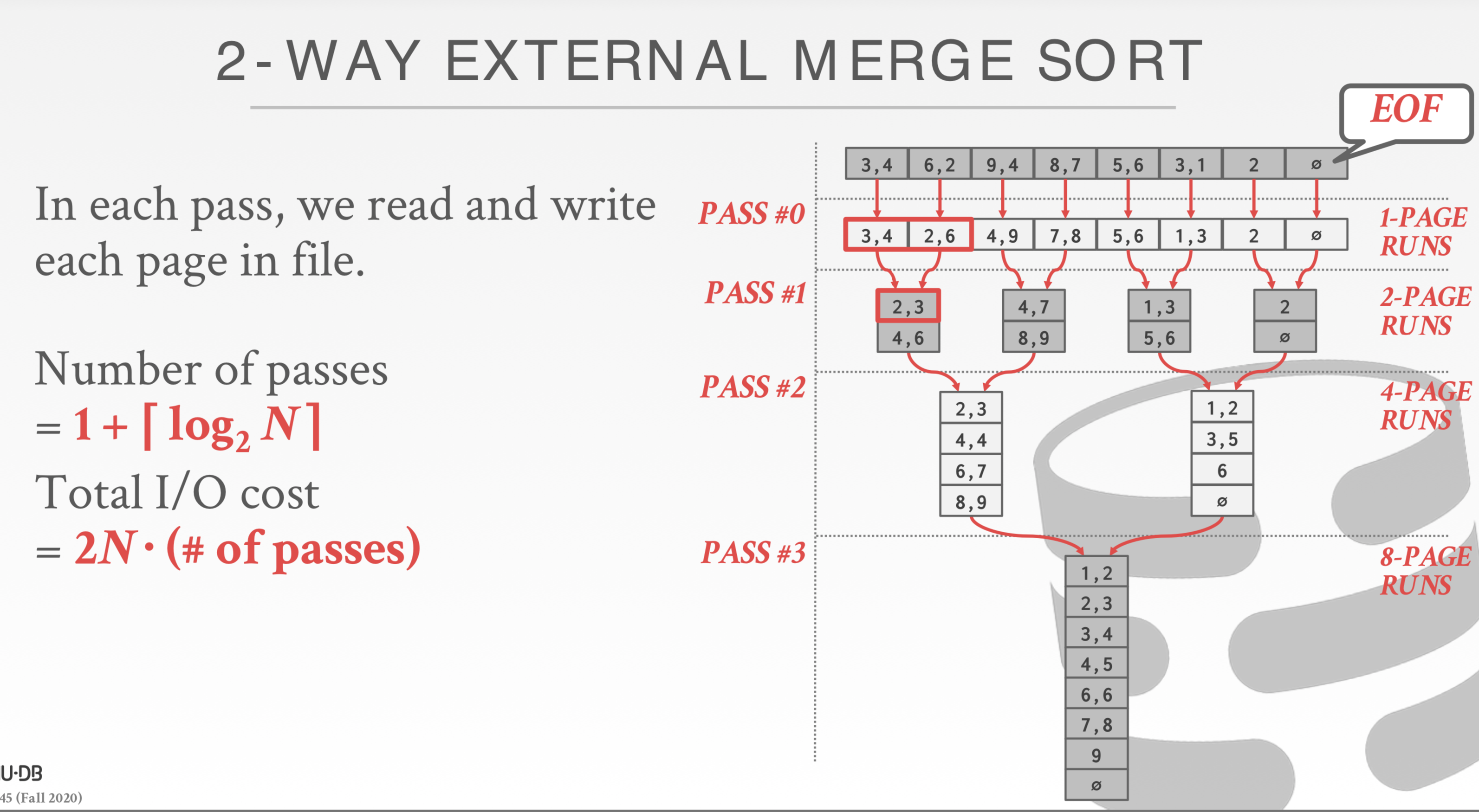
11. GROUP BY 、DISTINCT 应该怎么做?
一般有两种聚合方法,一种是Sorting Aggregation,另一种是Hashing Aggregation。
当然第一种排序聚合的方法需要做一遍外排,然后按顺序即可轻松进行GroupBy和Distinct操作,不过这样的方法开销会大一点,一般对于无排序要求的情况会采用Hash聚合。
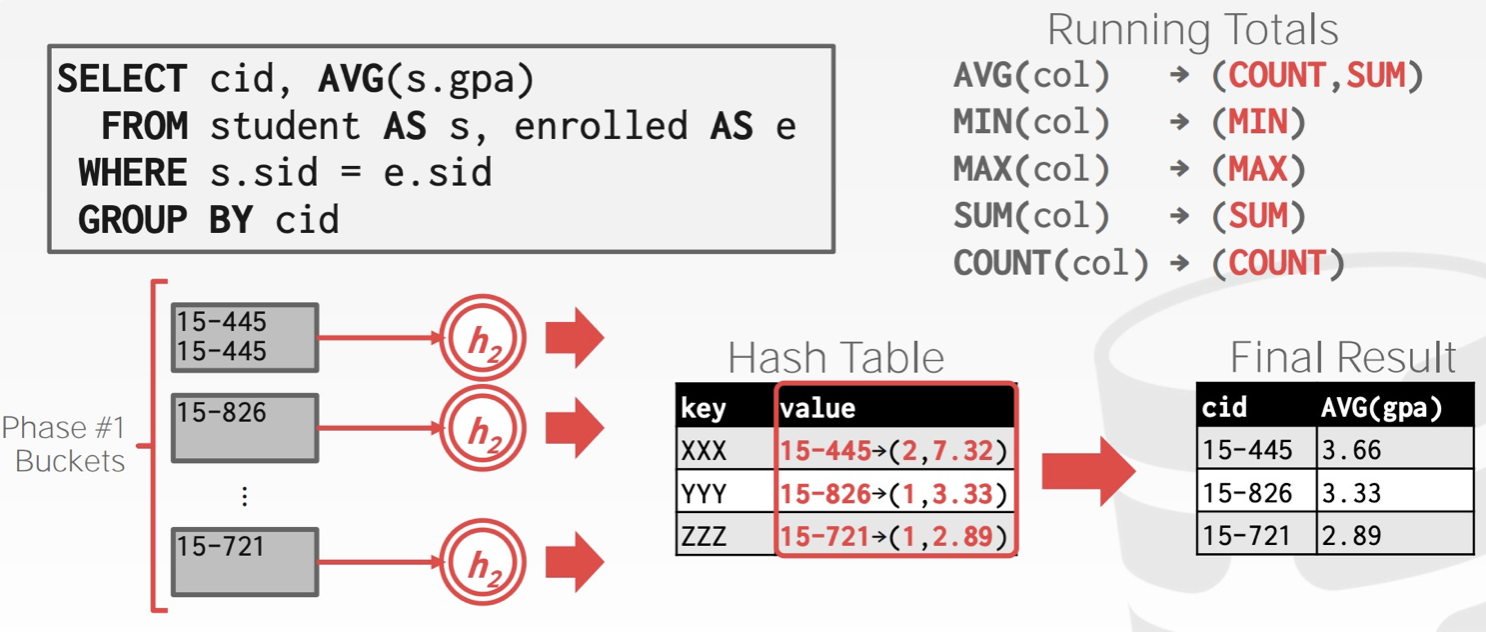
Hash聚合利用一个临时的Hash Table来记录必要的信息。
- 首先将相同的key哈希进一个partition中(使用 1 个 page 读数据,B-1 个 page 写出 B-1 个 partition 的数据),partition满了就刷进磁盘。
- 在内存中针对每个 partition 利用一个临时的Hash Table计算 aggregation 的结果
- 如果我们发现相应的 GroupKey 已经在内存中,只需要更新 RunningVal 就可以
- 反之,则插入新的 GroupKey 到 RunningVal 的键值对
由于这里的两阶段假设一个Partition可以被完整得读入内存之中因此能够聚合的表最大为 B × (B − 1)。
如果表更大,则阶段要更复杂一点,需要更多轮。
12. Join如何做?
这里只讲两张表的Join。
Join方法很多,最直观的就是一个对于A表的每一个Tuple,去遍历B表找到满足要求的Tuple合并。这也叫Nested Loop Join。一个很直观的优化就是两表Join,选数据量小的表作外循环(表的tuple数量一般远大于page数量,小表的tuple * 大表的page数的IO 一般 < 大表的tuple * 小表的page数)。如果Join的对象在两表都有索引也可以避免内部循环,可以直接找到对应的项。
还有优化的做法是可以用Sort-Merge Join。先分别对外层表和内层表按照JOIN KEY 要做好排序。然后Merge时同时从两表的一端开始双指针扫描去配对。这里要注意的是如果JOIN KEY不唯一可能需要外表指针回溯,内表指针无论Key唯不唯一都可能回溯。
Boss方法就是Hash Join:核心思想就是满足Join条件的Tuple对于JOIN KEY进行哈希必然相等。因此只需对两个表中哈希得到相同值的Tuples分别进行Join操作即可。
我们可以对2个表的数据分别PARTITION 到不同文件,用相同的HASH 函数。随后读出这2个文件,2重FOR循环。如果一次PARTITION还是没法全部读进内存。可以使用第2个HASH函数。
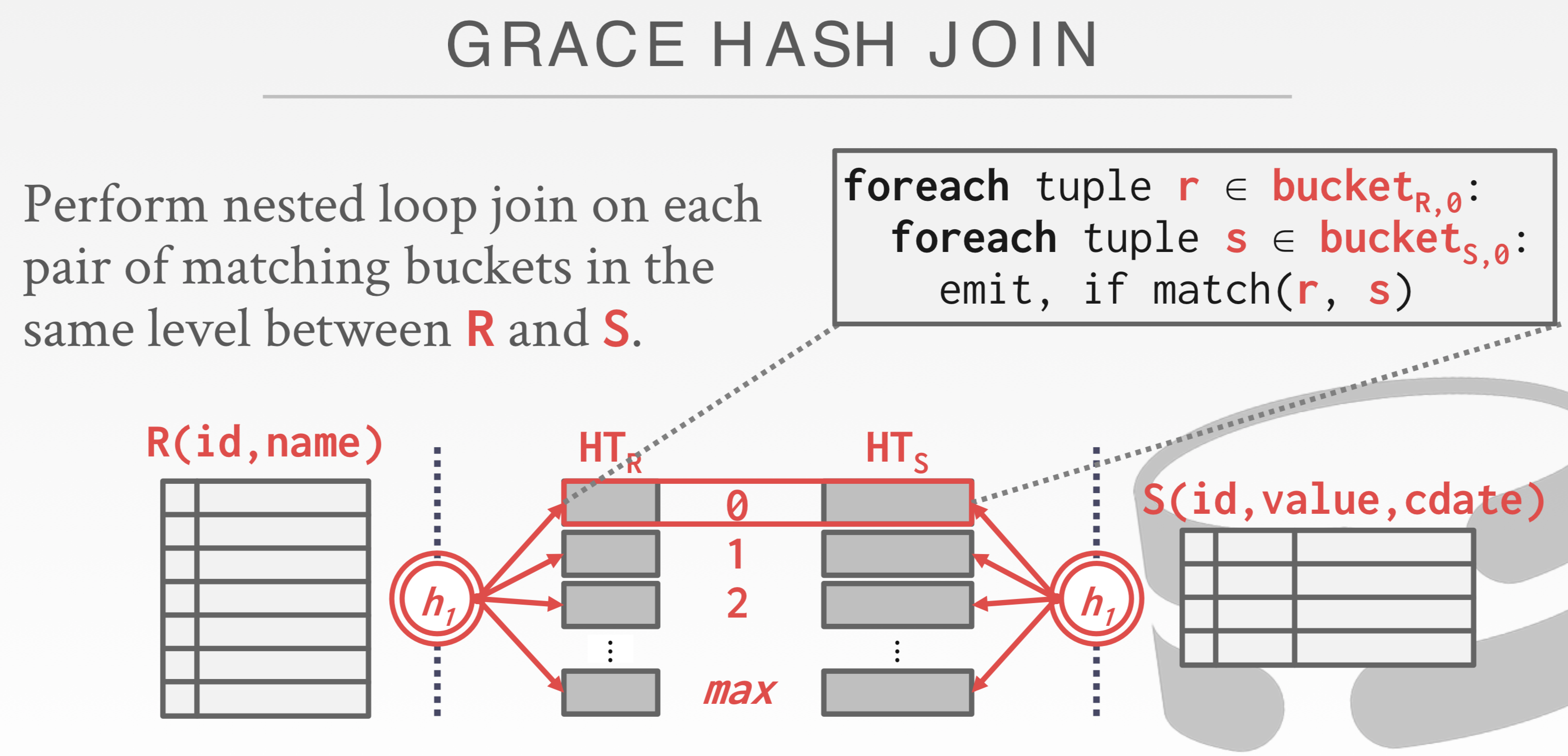
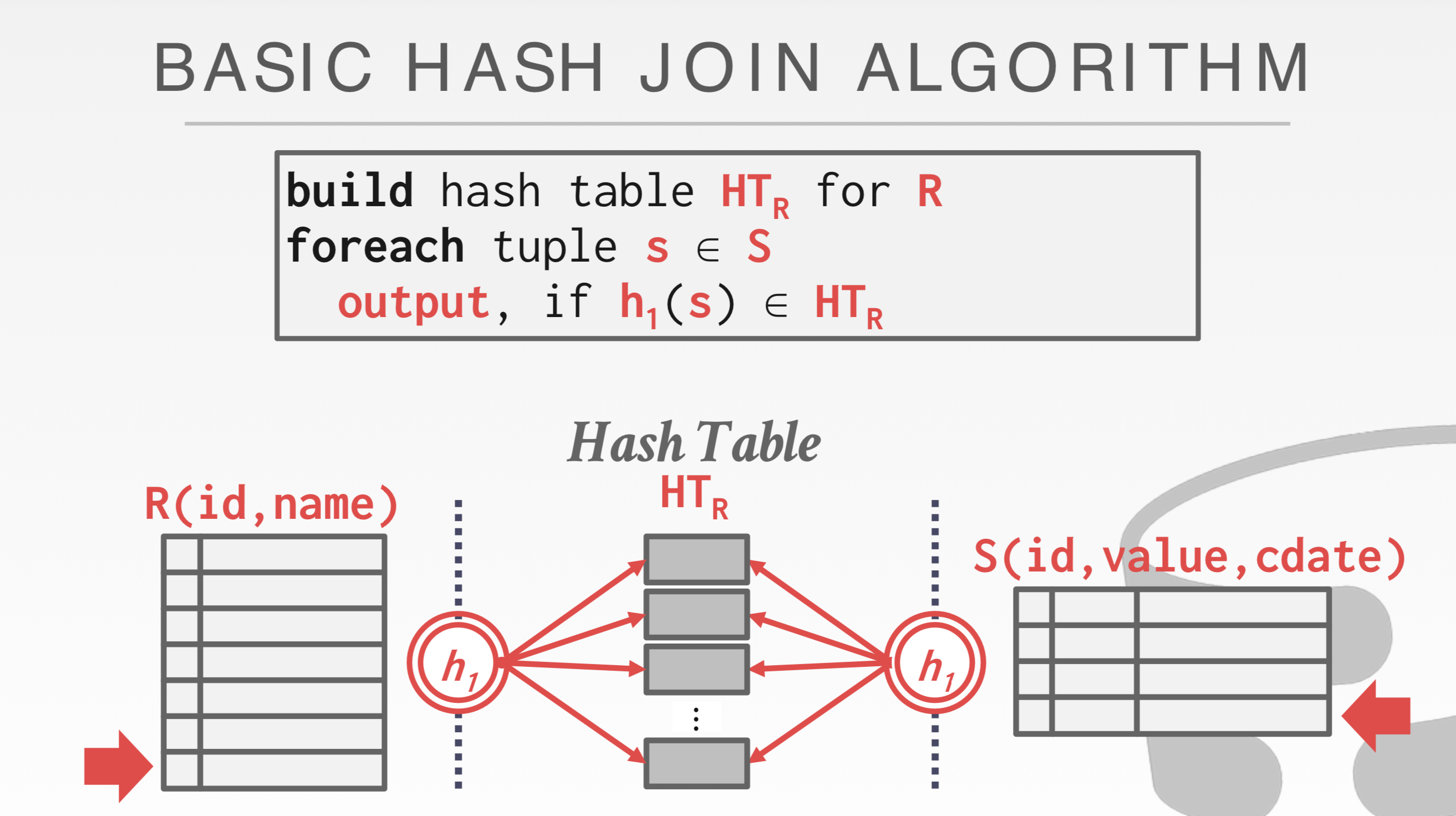
对于basic hash join,如果想更快检测s表tuple是否在哈希表中(哈希表如果太大无法全放在内存中),还可以在创建哈希表时使用布隆过滤器!
查询过程与优化
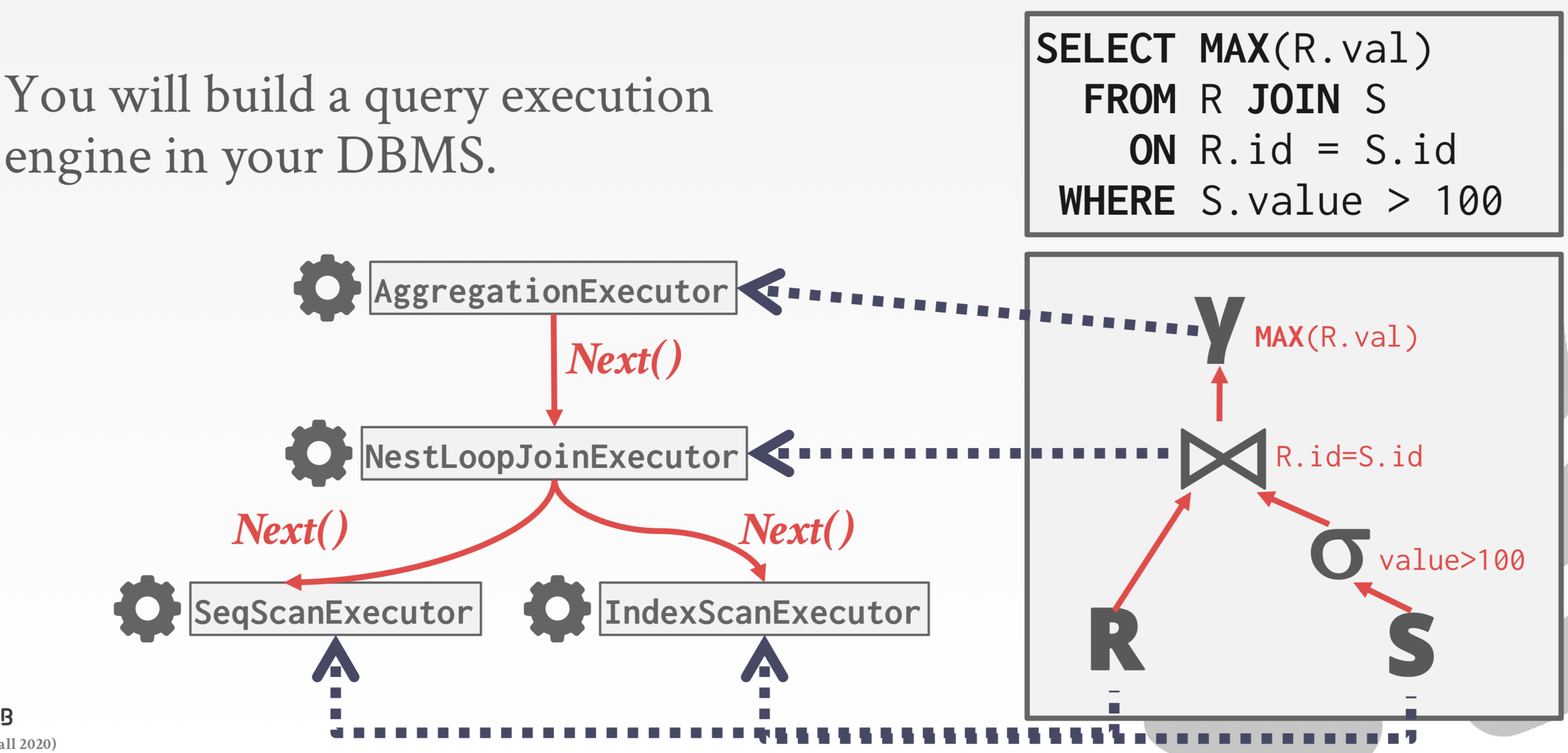
13. 描述一下一个执行计划数据系统是怎么做的?
Iterator迭代模型。每一个关系函数会实现自己的NEXT方法,下层的NEXT函数会被上层的算子调用。构建出自己的NEXT函数。而根节点的NEXT函数,就可以直接取到这个QUERY 要的一行行数据。
Materialization物化模型则是把数据准备好一齐返回给上层,而迭代模型是流式的。
Vectorization矢量模型是一个折中,它会暴露NEXT函数,之后是批量返回需要的数据。
| 模型 | 方向 | Emits | 使用场景 |
|---|---|---|---|
| Iterator/Volcano | Top-Down | Single Tuple | General Purpose |
| Vectorized | Top-Down | Tuple Batch | OLAP |
| Materialization | Bottom-Up | Entire Tuple Set | OLTP |
14. 描述一下几种常见的访问数据的方法?(access method)
三种方法:顺序扫描、索引扫描与BITMAP SCAN(用多个索引,求交集之后再返回结果)
最基本的就是顺序扫描。数据库维护一个当前扫完的页的指针。优化方式有,预取,缓存池绕过,统计信息检查(比如这页的最大值是300,你要查400以上的数据,就可以跳过该页),延迟物化,这里就是每个算子知道上层用不到哪些列,可以去更新OFFSET,让上层可以不用管他用不到的列信息。
其次是索引扫描,就是优化器会挑选最适合的索引去走索引文件。当然如果走非聚集索引,需要回表,这里有一个优化就是,把那些要回表的PAGE ID先存起来,然后把PAGE ID 排序,这样就可以顺序把需要的PAGE 都取好,读起来会比查一个找一个快很多。
15. WHERE语句的判断是怎么实现的?
DBMS 使用 expression tree 来表示一个 WHERE 语句。然后根据 expression tree 完成数据过滤的判断,即依次取算看树根最后是不是TRUE,但这个过程比较低效,很多 DBMS 采用 JIT Compilation 的方式,直接将比较的过程编译成机器码来执行,提高 expression evaluation 的效率。
16. QUERY 是怎么从用户输入到最后变成可执行的计划的?
首先SQL QUERY会经过重写器,这里会根据一些固定的模式对QUERY做改写,随后会经过PARSER生成一颗语法树,语法树的节点去查system catalog会把一些人可以读懂的关键词转换为系统内部的INTERNAL ID。 然后交给tree rewriter看下这颗树可不可以优化。到这里产生出了逻辑计划。逻辑计划结合一些基于统计样本的COST MODEL 再做一层优化生成出物理执行计划。
常见的基本逻辑优化有谓词下放(提前缩小数据行范围)、投影下方(提前缩小数据列范围)、一些表达式重写(表达式删除,合并谓词,连接消除等)
17. 说一下物理计划的优化?
这应该是数据库最最最最难的部分了。
首先就是基于统计,数据库会对每个表计算一些统计信息。比如最常用的就是一个列的选择度。就是这个列的DISTINCT值。 然后如果假设这些值分布均匀我们是可以估计出所有谓词的选择度, 比如范围: sel(A >= a) = (Amax − a/(Amax − Amin))。如果不均匀,也有2种方法,一种是建立均匀的桶。 这里其实是一道算法问题。就是给你每个KEY 的FRENCY,你要装进10个桶,使得每个桶的SIZE的差值最小。
另外一种方式是抽样。根据抽象数据去判断谓词的选择度。这个选择度在JOIN TABLE时非常重要,我们希望外层表越小越好。
下一步优化器会枚举出所有的可能的执行计划,并且计算他们的COST,然后选择COST最小的一个。对OLTP来说,这通常是简单,因为只要选对最佳的INDEX就可以。
但是OLAP通常会有多关系JOIN,随着JOIN数量增多,计划数的可能呈指数上升。
IBM最开始引入只考虑LEFT-DEEP JOIN(剪枝), 是为了更好的利用PIPELINE,这样可以不用把JOIN出来的结果序列化到磁盘。可以流式的去做。
接下来的可以枚举所有LEFT-DEEP TREE的顺序,枚举每个JOIN是用哪种JOIN算法,枚举每个表是用INDEX SCAN 还是SEQ SCAN。 然后用动态规划的方式取算出最小的代价的方式。如果要JOIN的表很多时,我们可以使用遗传算法来找到较优解。
并发控制
这里先简单讲一下数据库中一个非常重要的抽象——事务。
事务最关键的就是四个特性 ACID:
A就是原子性,事务里的操作要么全做成了,要么全没做成。这个背后的机制可以使用LOG来实现,也可以通过SHADOW PAGING来实现。
C是一致性,代表执行事务前如果状态是一致的,那么之后也是一致的。(这也是最终目的)
I是隔离性,虽然有很多事务会并行在做,但是每个提交的事务自己看上去会是只有自己在做。就是并行的事务不会相互影响。
D就是可持久性,所有事务提交的数据不应该丢失。
对于并发控制主要就是I(隔离性)的相关问题。
对于两个事务,不同事务中的操作穿插执行会带来一些错误。因此需要一些控制策略去限制操作的执行顺序。
对于限制操作执行顺序的程度,常见事务的隔离程度分为三个级别:read committed、snapshot/repeatable read 以及 serializable。相关竞争条件罗列如下:
| 竞争条件 | 描述 | 最低有效隔离级别 |
|---|---|---|
| 脏读 | clientA 读到 clientB 写入但还未 commit 的数据 | Read Committed |
| 脏写 | clientA 覆盖 clientB 写入但还未 commit 的数据 | Read Committed |
| 不可重复读 | client 在事务进行的不同时间点上读取不同状态的数据 | Snapshot Isolation |
| 更新丢失 | clientA 和 clientB 同时执行一个 read-modify-write 事务,clientA 在 clientB 不知情的情况下覆盖了 clientB 写入的数据,数据丢失且失去记录。 | Snapshot Isolation |
| 幻读 | clientA 根据某种搜索条件读取一组数据,同时 clientB 正执行的写操作改变着 clientA 读取的数据集合。 | Snapshot Isolation |
| 写倾斜 | clientA 读取某数据,并根据该数据的值做出另一个写数据的决定,然而在 clientA 写数据时,它读取的数据被 clientB 写入新的值,这使得 clientA 之前的决定的假设不成立 | Serialization Isolation |
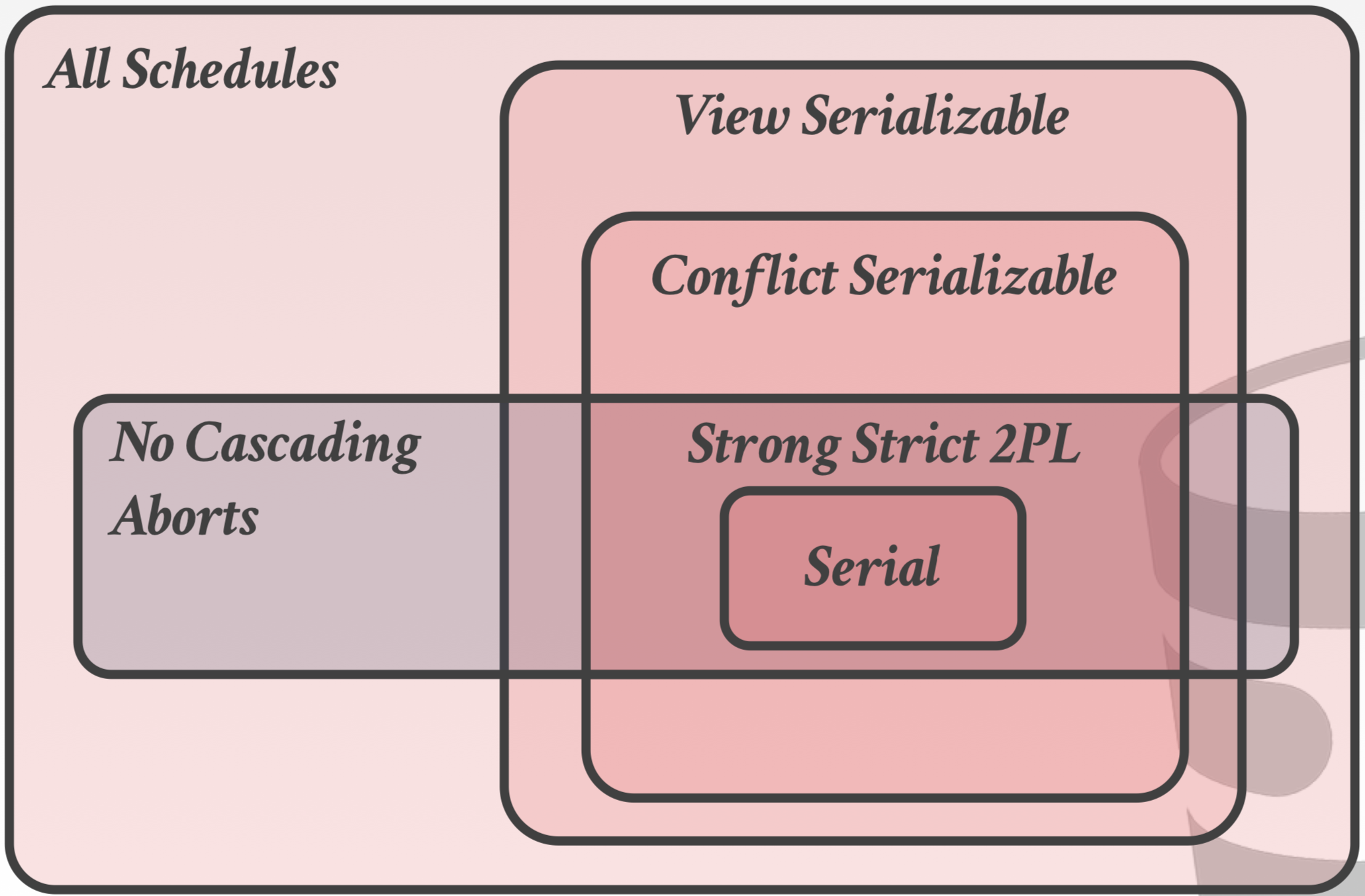
弱事务隔离级别只能保护应用不受以上竞争条件中的部分情况影响,因此应用开发者需要对数据库提供的保证有正确的了解,只有 serializable isolation 可以防止以上所有竞争条件带来的影响。
通过MVCC多版本并发控制这一
基础设施可以轻松实现Read Committed和Snapshot Isolation。
对于Serialization Isolation则有悲观与乐观两大类方法去实现。 悲观主要方法是2PL,乐观的主要方法是OOC。
18. 什么是2PL?
简单来说就是一个事务拿锁和还锁分为2个阶段,第一个阶段你可以拿,一旦你还了就到了第二个阶段,之后就不能再拿锁了。不过普通的2PL会造成级联Abort。比如第一个事务上来拿了锁A,并还了A,第二个事务拿到A开始做事情了,然后第一个事务ABORT了。第二个事务也只能ABORT。
如果不级联ABORT,就会脏读。当然还会引起死锁的问题。解决脏读问题可以靠严格二阶段锁定。严格2PL只在再事务结束时才释放所有锁。
19. 死锁发生了怎么办?
两个办法,一是启用一个线程进行死锁检测,数据库系统会构建事务之间锁依赖的有向图,如果有环就代表有死锁了。当发现了环,他会选择一个要事务去让他ROLLBACK来打破这个环。这个被牺牲的事务可以ABORT或者重试。这中间是对检测死锁的频率,和事务的等待死锁解开时间的trade-off。
二是死锁预防。在申请已被持有的锁时就根据锁持有方的优先级(新/老程度等)决定等待或是抢锁(或自身回滚)。
20. 如果一个事务要更新10万行,那他要拿10万把锁吗?
不需要,这里涉及到锁的粒度。粒度可以是TUPLE,可以是PAGE,也可以是TABLE。这里会引入意向锁,可以提高并发度,以及减少实际需要的锁用量。在父节点上IS(意向共享锁),代表需要在之后需要更细粒度的S LOCK。 如果上的是IX,就意味在接下来更细粒度需要X LOCK。 SIX 锁就等价于上了S锁 加IX锁。2个规则是如果要上S或者IS锁,那么父节点必须要有IS锁。如果要上IX,X,SIX,那么父节点必须要有IX锁。
当获得太多的细粒度锁的时候,锁会升级为粗粒度的锁。
21. 什么是OOC?
乐观锁其乐观表现在事务访问数据时无需显式加锁(通过附带时间戳等信息进行检测),主要原理是在发生不符合规则的冲突后解决冲突,重启事务。
OCC 分为3个步骤,READ、VALIDATION、 WRITE。核心思想就是先把数据库的内容读到自己的私有空间,要在提交时,去检测有没有和其他的事务有读写冲突,或者写读冲突。这里分为forward validation 和 backward validation,如果顺利,就可以进入write phase 把自己私有空间的内容刷进DB。OCC的问题是有复制数据的OVERHEAD,还有VALIDATION 和写是瓶颈,如果发生了ABORT,浪费的操作比2PL更多(因为没法提前知道出了问题,直到VALIDATION PHASE)
22. 简单介绍一下MVCC?
早期数据库不论读取还是写入,都用锁来实现。但是锁会带来性能的问题。人们尝试各种优化方案。写入和读取的优化方式不同。对于写入操作,没有特别好的办法,人们实现主要就是上述几个问题的乐观锁与悲观锁。而对于读取操作,优化就是MVCC,对数据库的任何修改的提交都不会直接覆盖之前的数据,而是产生一个新的版本与老版本共存,使得读取时可以完全不加锁。
MVCC是一套很大的概念。主要思想是想要读不阻塞写,写不阻塞读。简而言之,实现 MVCC 的 DBMS 在内部维持着单个逻辑数据的多个物理版本,当事务修改某数据时,DBMS 将为其创建一个新的版本;当事务读取某数据时,它将读到该数据在事务开始时刻之前的最新版本。由此非常容易实现Read Committed和Snapshot Isolation两个隔离级别(如实现可重复读即总是读取当前事务开始之前最后一次commit的版本)。
它分为4块组成。
第一块是选择一种并发控制协议,比如可以是T/O, OCC, 或者2PL。
第二块是存多版本的方法。
第三块是垃圾回收的方法,分为TUPLE级别的GC和事务级别的GC。
第四块是索引管理。
细节太多部分感兴趣的读者可以自行查阅… …
故障恢复
关于可靠的持久性。首先数据库要采取一些行动在当事务正在运行的时候,来保证DBMS可以从失败恢复。然后在重启的时候需要采取一些动作来恢复之前的状态确保ACID的性质。
23. 事物在执行时需要采取什么行动来确保故障能够恢复?
WAL(Write Ahead Log)。另一种Shadow Page的方法不怎么用就不说了。WAL使用的是Steal + No force策略,即BUFFER POOL可以在事务未提交前,就把脏页刷到磁盘;并且事务在提交时不一定要把事务涉及到的脏页全部刷盘。
那么关于WAL什么时候刷入磁盘。一种是当一个WAL LOG BUFFER PAGE写满的时候,会触发一次刷盘。同时第二个页可以用来写,这样性能非常好,另外一种情况,就是过了一定的时间,也会触发一次刷盘。其次就是事务提交时会触发刷盘。
WAL的日志具体记录什么样的Log分为3种格式:一种是物理日志,存的就是具体的页的位偏移改了什么。缺点是如果一个SQL改了10W条数据,那么就会有这么多的LOG信息。优点是更加细节,不易出错,更容易恢复。另一种是逻辑日志,基本就是把SQL语句给存下来。优点是磁盘占用空间小。缺点是并发事务时日志会不准,数据可能会不一致。而且恢复起来会更慢。最后一种是半物理日志,他存的是具体的页的数据信息但是和页的数据组织无关。会更加通用,且易在上面做优化。可以其他下游系统去读取。
DBMS会周期性的打CHECKPOINT, 凡是打了CHECKPOINT的位置在这之前已经COMMIT的TX一定是已经落盘了。所以关于这些的WAL就可以回收掉的。最简单的打CHECKPOINT的方式就是停掉所有TXN,然后开始刷盘,然后再日志上打一个CHECKPOINT记录。然后恢复停掉的TXN继续做。所有在CHECKPOINT后开始的事务,在CRASH前没提交,需要UNDO。在CRASH前提交了,需要REDO。
24. 在故障发生后如何恢复数据库?
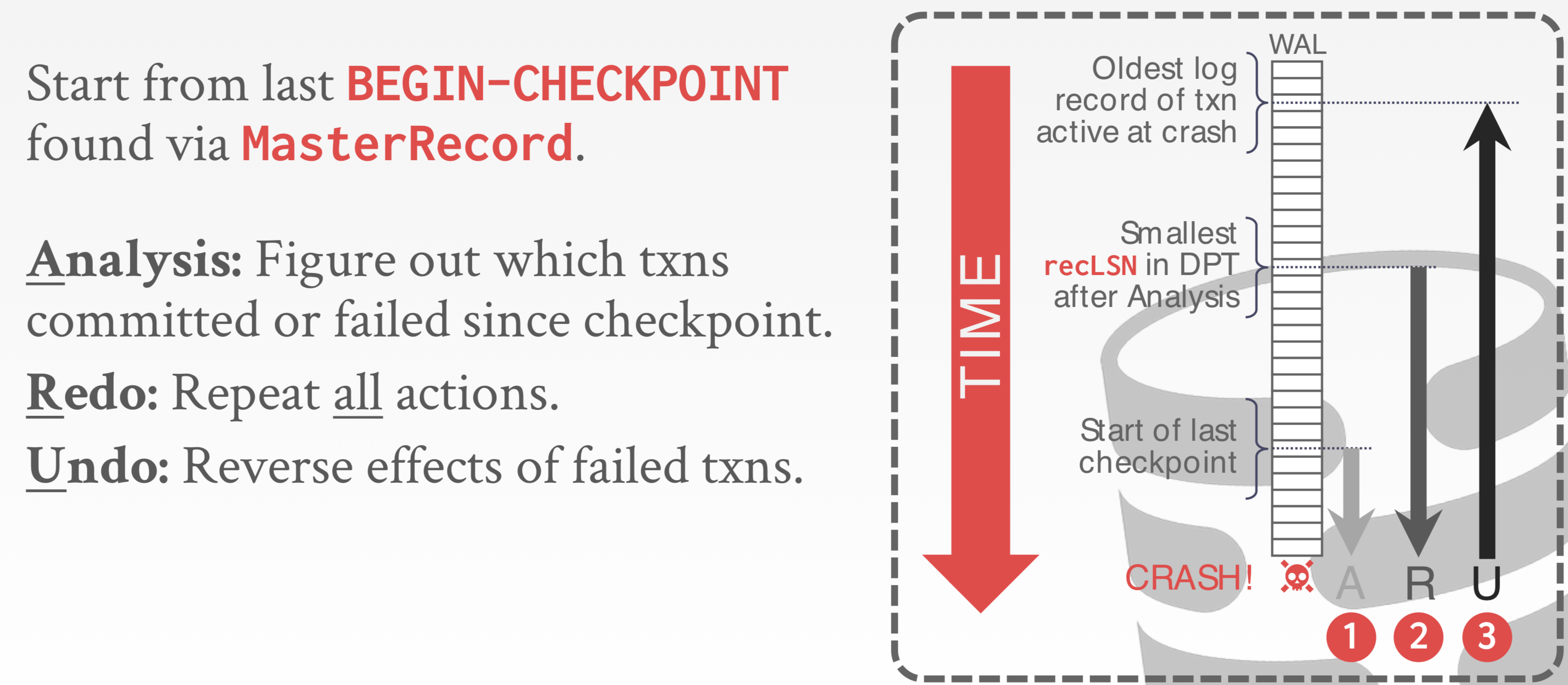
ARIES。此机制肯定要借助WAL。
第一步是分析,目标是得到CRASH时刻的ATT和DPT,从MASTER RECORD开始读所有日志,然后更新ATT(活跃事务表)和DPT(脏页表)。
第二步是根据DPT里最小的LSN (日志序号)我们就可以把这之后的所有操作都在内存中REDO,如果有TXN-END,就可以更新ATT。
第三步是就是余下的ATT表里都是没做完的TXN,需要UNDO,把他们UNDO掉。
关于Fuzzy checkpoint:其实就是内存中维护了ATT和DPT两张表,Checkpoint只是将这两张表写入到了日志之中,并没有将实际所有脏页刷盘(所以不会阻塞活跃的事务)。分析阶段就是从Begin开始重建这两张表,Redo阶段即要从DPT里最老的脏页LSN开始了。
分布式相关
这部分和DDIA、MIT6.824重合很多。主要介绍了解决分布式事务问题的2PC、Paxos算法与分布式数据库的数据复制与数据分区技术。
对于分布式未来学习完MIT6.824会进行新的知识点总结复习,在数据库课程中自己理解得也不是很到位就不做知识点复习了。
CMU15-445课程总结
以前本科的数据库课程仅仅教了如何使用数据库,在学习完CMU15-445与完成Lab的过程中才真正了解到一个简单的关系型数据库是如何诞生的。Andy的PPT做得真的很精美,描述很多问题的图都非常的清晰。
并且在课程中也提到了很多不一定要用在数据库领域里但非常有用的技术如Bloom Filter、一致性哈希算法等,属实拓展了一定知识面。虽然分布式相关知识我没做复习点总结,但其实那节课涉猎了很多概念例如云原生数据库、Serverless数据库等。收获真的很大。
前路漫漫,继续探索吧!
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!